
About the project
Objective
This research aims to create a strong framework for Online Continual Learning (OCL) that will help AI models learn gradually from streaming data. It will tackle the catastrophic forgetting phenomenon and maintain long-term flexibility, with a focus on high-stakes, changing environments where models need to adjust quickly without retraining. This is especially important in healthcare and other real-world areas where data changes constantly and unpredictably.
Background
Traditional AI models, especially in Deep Learning (DL), are usually trained on fixed datasets and used as set systems, making them fragile in changing situations. When new tasks or data come up, these models either need expensive retraining or risk forgetting what they previously learned. This inflexibility limits their growth and usefulness in real-world scenarios
Online continual learning changes this by allowing models to update continuously as new data comes in, much like how humans learn over time. However, this approach brings complex challenges, such as finding a balance between stability (keeping old knowledge) and plasticity (adjusting to new information).
Finding this balance in high-dimensional areas is particularly hard, as updates need to happen in real-time while following strict memory and processing limits. Take healthcare as an example: patient profiles and medical knowledge change every day. AI systems must keep up without sacrificing safety or accuracy. The implications go beyond healthcare. They also include autonomous systems that must navigate changing environments and adaptive vision models that need to stay relevant amid ever-changing data streams.
About the Digital Futures Postdoc Fellow
Romeo Lanzino is a researcher in Artificial Intelligence. He focuses on Computer Vision, Continual Learning, and , bioinformatics . He is currently a postdoctoral researcher at KTH Royal Institute of Technology, where he’s researching adaptive AI systems that can learn continuously from changing data streams. He earned a PhD in Artificial Intelligence at Sapienza University of Rome (Italy) under the Italian National PhD AI program. His doctoral research looked closely at how Deep Learning is used for analyzing physiological signals, questioning common beliefs about how well neural networks perform in Electroencephalography studies. He has a background in computer science from Sapienza, where he received both his BSc and MSc with honors. Romeo is active in the academic community as a reviewer for top venues like ICCV, NeurIPS, and IEEE Transactions on Multimedia, and he also co-organizes related workshops at major conferences.
Main supervisor
Atsuko Maki, KTH
Co-supervisor
Josephine Sullivan, KTH
About the project
Objective
This project aims to build mathematical foundations and design efficient algorithms for problems on metric graphs. The research will proceed in two stages. First, the focus will be on developing geometric and topological methods to construct or reconstruct metric graphs from real-world data. Second, the project will address the extraction of statistical information and the solution of applied problems on metric graphs through optimization-based approaches.
Background
Metric graphs offer a powerful way to model real-world data that has an underlying network structure together with spatial attributes. Examples of metric graphs include road networks, brain connectivity networks, and social networks. Unlike tabular data which is well-structured, metric graphs are inherently complex and nonlinear. Existing methods are ill-suited for computational and practical analysis of metric graphs, which limits their utility as models for real data. My research aims to provide an essential framework for applications of metric graphs in machine learning and data science.
About the Digital Futures Postdoc Fellow
Yueqi Cao completed his PhD in mathematics at Imperial College London in 2025. He works on applied and computational mathematics and statistics, with a particular interest in geometric and topological data analysis. Prior to that, he obtained master’s degree and bachelor’s degree in mathematics from Beijing Institute of Technology.
Main supervisor
Johan Karlsson
Co-supervisor
Sandra Di Rocco
About the project
Objective
This project aims to create a real-time digital twin framework enhanced with physics-informed neural networks (PINNs) to guide the development of plant-based meat analogs. By integrating mechanistic modeling with AI, the framework will provide deeper insight into protein structuring and deliver accurate, efficient tools for predicting and optimizing texture.
Background
Food production is a major driver of climate change, biodiversity loss, and public health challenges. While the transition to plant-based diets offers clear sustainability benefits, consumer acceptance is limited by the difficulty of reproducing the texture of meat. Current development approaches rely on costly, time-consuming trial-and-error experimentation. This project pioneers a systematic, data- and physics-driven strategy to accelerate texture design, reduce development costs, and enable more sustainable, nutritious, and appealing plant-based foods.
About the Digital Futures Postdoc Fellow
Jingnan Zhang holds a PhD in Food and Nutrition Science. Her research integrates computational modeling and soft matter physics with food science, enabling a systems-oriented approach to connect digital technologies with sustainable and resilient innovations for the future of food.
Main supervisor
Francisco Javier Vilaplana Domingo, Professor, Department of Chemistry, KTH Royal Institute of Technology.
Co-supervisor
Anna Hanner, Associate professor, Department of Fibre and Polymer Technology, KTH Royal Institute of Technology.
About the project
Objective
There are abundant unlabeled and noisy data in research fields of modern biology and medical science. Naturally, estimating biological structures and networks from unlabeled and noisy data widens the scope of future AI-based research in biology, with directly actionable effects in medical science. The major technical challenge is development of robust AI and GenAI methods that can use information hidden in unlabeled and noisy data. A promising path to address the challenge is to include a-priori biological knowledge in developing models for signals and systems, and collecting data, and then regularize the learning of AI methods.
In pursuit of addressing the challenge, we focus on inference of gene regulatory networks (GRNs) from their noisy gene expression level data – a challenging inverse problem in biology. Understanding and knowing a GRN is a key for understanding biological mechanisms causing diseases such as cancer. While gene expression data is available in abundance, the data is unlabeled due to absence of knowing the true GRNs underneath. In addition, the expression data is noisy. So far, use of AI for robust estimation of large-size GRNs from unlabeled and noisy gene expression level data has been little exercised. Indeed, learning from unlabeled and noise data is challenging for AI methods. Here comes the motivation for the proposed project – Biology-informed Robust AI (BRAI). The objective of the BRAI project is to develop fundamental theory and tools for inferring complex biological structures and networks from unlabeled and noisy data using a-priori biological knowledge, focusing on the challenging inverse problem ‘GRN inference’.
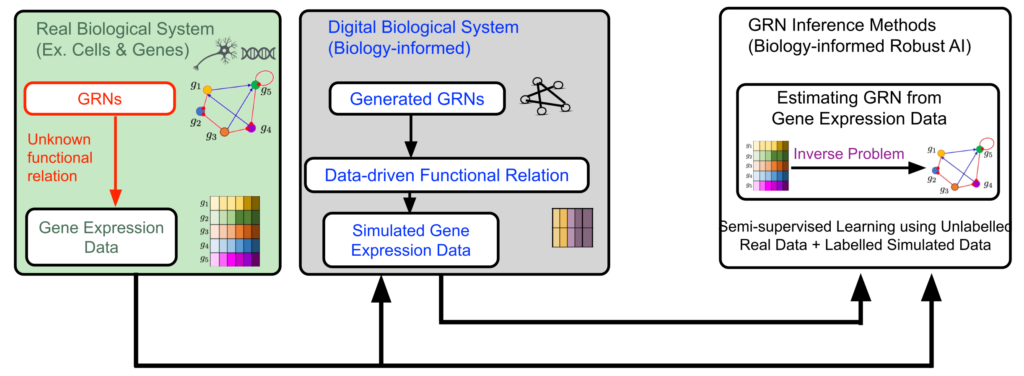
Background
The human reference genome contains somewhere between 19,000 – 20,000 protein-coding genes. For human cells (ex. cancer cells), GRNs are large. In reality, the GRNs are not observed directly. They are observed through the gene expression data. Therefore, it is difficult to collect labeled data as pairwise GRN- and -expression data for training AI and machine learning (ML) in a standard supervised learning approach. On the other hand, there are gene expression data available in abundance as unlabeled data, without the true GRNs underneath.
The actual functional relationship between a GRN matrix and its expression data is governed by complex biophysics. For complex biological systems like cancer cells, the true functional relationship governing GRN-to- expression data is unknown, and difficult to model. In addition, the gene expression data is noisy, as the expression data contains not only information from the hidden GRN, but other known-and-unknown biological events.
Naturally, the GRN inference problem – estimating a large GRN from its noisy gene expression data without having labeled data and knowing their actual functional relationship – is a challenging inverse problem.
Cross-disciplinary collaboration
The project will combine methods and techniques from separate research fields – (a) biological knowledge about GRNs from bioinformatics and system biology, (b) graph theory and topological data analysis for network modeling from mathematics, and (c) robust machine learning (ML) and GenAI from AI / ML.
About the project
Objective
This project aims to advance the understanding of flexible protein dynamics by developing novel algorithms that integrate cryo-electron microscopy (cryo-EM) data with computational predictions using generative AI and statistical modeling. The goal is to overcome current limitations in protein structure prediction by accurately reconstructing continuous, atomic-resolution 3D structures and their dynamic variations. Ultimately, the project will provide transformative tools for the global life sciences community, enhancing insights into molecular functions critical for health, biotechnology, and medicine while strengthening Sweden’s leadership in AI4Science.
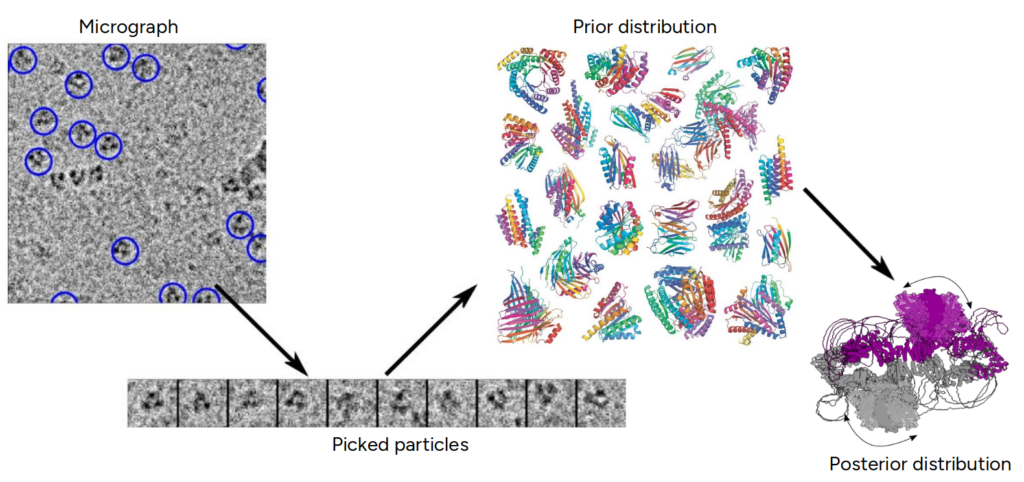
Background
Understanding the dynamic structures of flexible proteins is a major challenge in structural biology, as these molecules undergo continuous conformational changes essential for their biological functions. While cryo-electron microscopy (cryo-EM) has revolutionized the visualization of biomolecules at near-atomic resolution, capturing their full dynamic range remains difficult. Current computational methods, including AI-based predictions like AlphaFold, often fall short in modeling the continuous motions and heterogeneity of flexible proteins.
This project builds on advances in cryo-EM imaging, statistical modeling, and generative AI to develop new approaches that can more accurately reconstruct and analyze protein dynamics, addressing critical gaps in both experimental and computational techniques.
Cross-disciplinary collaboration
The project brings together experts from mathematics, machine learning, and structural biology to tackle complex challenges in biomolecular dynamics. Mathematicians contribute advanced statistical and inverse problem-solving techniques crucial for developing robust reconstruction algorithms. Machine learning specialists develop generative AI models to create data-driven priors that enhance the interpretation of cryo-EM data.
Finally, structural biologists provide essential expertise in cryo-EM methodologies, including sample preparation and image processing, ensuring high-quality experimental data, but more importantly provide critical domain expertise in order to design and evaluate the proposed methods.
About the project
Objective
- O1. Co-creation of a transformative user-centered design framework that integrates the lived experiences, preferences, and embodied interactions of older adults, paving the way for socially inclusive and empathetic SSRE designs that redefine mobility support.
- O2. Integration of biomechanical sensing, modeling, and control systems that seamlessly blend human intention, somatic feedback, and emotional cues, enabling SSREs to adapt dynamically and intuitively to the user’s physical and emotional states.
- O3. Development of human-SSRE interaction techniques through cutting-edge sensory-actuator designs, utilizing soft robotics, adaptive rhythms, and somatic alignment to create an unprecedented sense of trust, safety, and user empowerment in mobility.
- O4. Assess real-world adoption of SSREs by conducting studies that capture the full spectrum of their impact—mobility, trust, dignity, and quality of life—while providing actionable insights to drive societal integration.
Background
Exoskeletons are increasingly recognized as a potential mobility solution for older adults, aiming to support independence and health in aging populations. Studies show promising results, such as improved walking speed, endurance, and alleviation of gait issues in neurological conditions (Tricomi et al., 2024; Lakmazaheri et al., 2024; Kim et al., 2024). However, most devices are not explicitly designed for older adults or real-world settings, often tested on young, able-bodied males, overlooking motor decline and the complexities of aging user interactions. Few studies explore older adults’ experiences with exoskeletons in daily life (Shore et al., 2018, 2020), and participation in design or long-term evaluations is rare (Young et al., 2022). Trust, comfort, and safety are critical factors for acceptability but remain underexplored in user-centered design (Peng et al., 2022).
Theoretical frameworks highlight that trust in autonomous systems stems from sensory and embodied interactions (Pink, 2021), while emerging approaches, such as soma design have the capacity to place sustained focus on the sensory, embodied and experiential aspects of interaction with technology (Höök 2018). Soma design approaches as applied to autonomous systems can enhance feelings of trust and safety in other domains, such as in semi-autonomous vehicles (Balaam et al., 2024). However, the mechatronic systems essential for replicating nuanced sensory interactions are underdeveloped.
Though advancements in materials, human-in-the-loop control, and sensor technology provide insights into user movement and needs (Küçüktabak et al., 2023), real-world applications often fail to achieve the real-time adaptability required for intuitive use. This represents a significant limitation in achieving devices that “feel right” and foster trust in users. In addition, the capability to measure and predict human motion and intention has not yet been fully translated into real-world applications. While simulations of optimal external assistance can estimate user responses to some degree, the complexity of human movement and interaction limits their accuracy. Thus, current systems lack synchronization, crucial for aligning user actions with device responses (Wilkenfeld et al., 2023). Addressing these gaps is key to fostering trust, comfort, and usability in exoskeleton design and achieving widespread adoption.
Cross-disciplinary collaboration
This project brings together a Professor in Biomechanics, alongside a Professor in Interaction Design and an Assistant Professor in Mechatronics, representing the KTH school of Engineering Science, the KTH School of Electrical Engineering and Computing Science and the KTH School of Industrial Engineering and Management. This cross disciplinary expertise will allow us to develop new exoskeleton interaction technologies will provide new ways for users and exoskeletons to cooperate, improving user experiences of safety, efficiency, and pleasure of moving with these assitive devices. By placing older adults at the centre of design and development processes towards exoskeleton we expect to redefine mobility for aging adults by combining physical functionality with psychological and emotional care.
About the project
Objective
This project will provide novel methodology to reconstruct the evolutionary history of cancer cells in their spatial context from widely used data. We will integrate single-cell and spatial transcriptomics data to reconstruct the evolutionary history of cancer cells and describe their spatial structure. These results will reveal how different cancer cell states arise and organize in space during tumor evolution, and how different states may be shaped by their interactions with the tumor microenvironment.
Background
Single-cell sequencing data has enabled highly detailed descriptions of intra-tumor heterogeneity in terms of the genotypes and phenotypes of cancer cells, as well as maps of the non-cancer cell types present within the tumor microenvironment. While standard single-cell sequencing techniques such as scRNA-seq provide detailed information on the cell states that make up a tumor, they do not capture the spatial distribution of the cells that it captures, which is lost in the process. In contrast, spatial transcriptomics technologies maintain the spatial structure of 2D tumor slices intact while still obtaining transcriptome-wide measurements of the cells therein. Integrating both data types may reveal novel therapeutic targets.
About the Digital Futures Postdoc Fellow
Pedro F. Ferreira holds a PhD in Computational Biology from ETH Zürich in Switzerland and a MSc in Electrical and Computer Engineering from IST in Portugal. He is interested in using single-cell sequencing data to reconstruct cell lineages and trajectories in order to identify key processes involved in tumor progression. To this end, Pedro has developed computational tools to characterize the populations of cells that constitute a tumor. These include learning the evolutionary history of cancer cells and identifying the gene expression patterns of malignant and normal cells. Pedro enjoys collaborating with biologists, bioinformaticians and machine learning experts in order to design powerful computational methods able to describe the heterogeneous populations of cells that constitute tumors.
Main supervisor
Jens Lagergren, KTH
Co-supervisor
Joakim Lundeberg, KTH.