
About the project
Objective
This project will complement our landmark, large-scale qualitative study of the first algorithmic contraceptive on the market – Natural Cycles – by examining the experiences of individuals who have previously used the service as a form of contraception but no longer subscribe to it. Our layered approach to trust also encompasses psychological, contextual and interpersonal factors that question and enliven current trust models in AI and algorithmic systems. Through the project, we expect to learn about what happens when trust in digital intimate health technologies breaks down and to co-design user experience mechanisms that respond to what an intimate digital health technology could do to re-establish trust when it has been challenged or lost.
Background
Algorithmic systems and Artificial Intelligence (AI) are poised to disrupt how we deliver and experience healthcare, providing new solutions to personal and public health issues. Trust has been identified as one key foundation for the success of digital health technologies. Mechanisms that promote trust are critical areas for research and innovation. Health interventions are often designed for use – and behaviour change – at an individual level. However, health choices, health behaviours, and critical trust in healthcare service providers are interpersonal and socially constructed. This calls for research on how trust is developed, experienced, and maintained between users and an algorithmic health service – but also what happens when something goes wrong with the technology or between the people using it as a part of an intimate relationship.
Crossdisciplinary collaboration
The researchers in the team represent the Department of Computer and Systems Sciences (DSV), Stockholm University, and the School of Electrical Engineering and Computer Science, KTH.
About the project
Objective
In Emergence 2.0, we aim to build reliable, secure, high-speed edge networks that enable the deployment of mission-critical applications, such as remote vehicle driving and industrial sensor & actuator control. We will design a novel system for enabling fine-grained network visibility and intelligent control planes that are i) reactive to quickly detect and react to anomalies or attacks in edge networks and IoT networks, ii) accurate to avoid missing sophisticated attacks or issue unwanted alerts without reason, iii) expressive, to support complex analysis of data and packet processing pipelines using ML classifiers, and iv) efficient, to consume up to 10x less energy resources compared to state of the art.
Background
Detecting cyber-attacks, failures, misconfigurations, or sudden changes in the traffic workload must rely on two components: i) an accurate/reactive network monitoring system that provides network operators with fine-grained visibility into the underlying network conditions and ii) an intelligent control plane that is fed with such visibility information and learns to distinguish different events that will trigger mitigation operations (e.g., filtering malicious traffic).
Today’s networks rely on general-purpose CPU servers equipped with large memories to support fine-grained visibility of a small fraction (1%) of the forwarded traffic (i.e., user-faced traffic). Even for such small amounts of traffic, recent work has shown that a network must deploy >100 general-purpose, power-hungry CPU-based servers to process a single terabit of traffic per second, costing millions of dollars to build and power with electricity. Today’s data centre networks must support thousands of terabits per second of traffic across their cloud and edge data centre infrastructure.
Crossdisciplinary collaboration
The researchers in the team represent the KTH School of Electrical Engineering and Computer Science, the Department of Computer Science and the Connected Intelligence unit at RISE Research Institutes of Sweden.
About the project
Objective
The PERCy project aims to develop a reference architecture, procedures and algorithms that facilitate advanced driver assistance systems and ultimately fully automated driving by fusing data provided by onboard sensors, off-board sensors and, when available, sensory data acquired by cellular network sensing. The fused data is then exploited for safety-critical tasks such as manoeuvring highly automated vehicles in public, open areas. This framework is motivated by the key observation that off-board sensors and information sharing extend the safe operational design domain achieved when relying solely on on-board sensors, thus promising to achieve a highly improved performance-safety balance.
Background
Advanced driver assistance systems – such as adaptive cruise control, autonomous emergency braking, blind-spot assist, lane keep assist, and vulnerable road user detection – are increasingly deployed since they increase traffic safety and driving convenience. These systems’ functional safety and general dependability depend critically on onboard sensors and associated signal-processing capabilities. Since advanced driver assistance systems directly impact the driver’s reactions and the vehicle’s dynamics and can cause new hazards and accidents if they malfunction, they must comply with safety requirements. The safety relevance of onboard sensors is even higher in the case of highly automated driving, where the human driver does not supervise the driving operation. However, current standards and methodologies provide little guidance for collaborative systems, leading to many open research questions.
Crossdisciplinary collaboration
This project is a collaboration between KTH, Ericsson and Scania.
About the project
Objective
The overall objective of the project is to shorten the time needed for securely and safely deploying software updates to vehicles in the automotive industry. The project will address this in the context of software development for heavy vehicles at Scania and the toolchain for automated formal verification of code in the C programming language developed in the previous AVerT research project, called Autodeduct, which is based on the Frama-C code analysis framework and its ACSL contract specification language for C code.
As specific goals, the project will (i) extend Autodeduct with techniques for incremental formal verification as software evolves, (ii) extend the toolchain with support for non-functional requirements in software contracts focusing on safety and security properties relevant to Scania vehicles and including control flow and data flow, (iii) evaluate the techniques as implemented in the new toolchain on relevant code from Scania’s codebase to determine their efficacy, and (iv) develop a case study applying the new toolchain to a realistic software development scenario that demonstrates its applicability in an industrial setting.
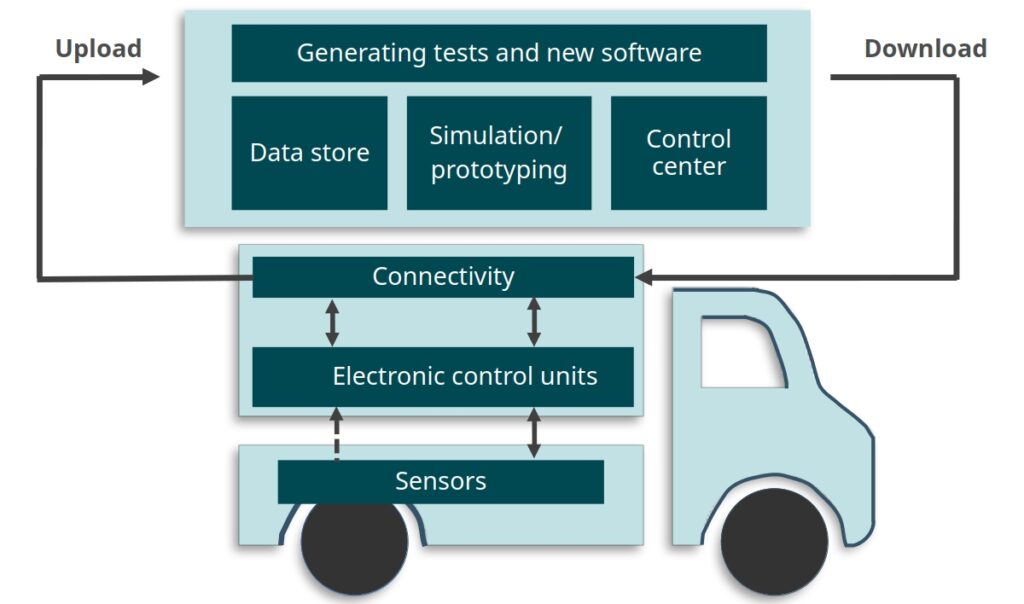
Background
In the automotive industry, digitization means that vehicles increasingly depend on and are comprised of software components, leading towards software defined vehicles where most functions are primarily controlled by software. However, vehicle software components need to be continually revised by manufacturers to fix bugs and add functionality, and then deployed to vehicles in operation. Development and deployment of such software updates is currently demanding and time consuming—it may take months or even years for a new software component revision to reach vehicles.
Delayed time to deployment for software updates is in large part due to the long-running processes employed for assuring the revised software system meets its requirements, including legal requirements and requirements on safety and security. Currently, these processes often involve costly analysis of a system in a simulated or real environment, e.g., by executing an extensive suite of regression tests. The time required for running such tests can potentially grow with the size of the whole software system, e.g., as measured by lines of code in the codebase. Regression tests may also fail to consider non-functional properties such as security. The project aims to enable more rapid and trustworthy incremental development of software in heavy vehicles with guarantees of safety and security. Trust is built in the vehicle software development process by adopting tools with rigorous mathematical guarantees.
Crossdisciplinary collaboration
The project partner is Scania CV AB.
Background and summary of fellowship
Fundamental bounds of information processing systems provide the limit on theoretically possible achievable performances. For instance, in communications, the information-theoretic Shannon capacity describes the fundamental bound on what communication rate can be maximally achieved with vanishing error probability. This fundamental bound can be then used as a benchmark for the actual system design. It is therefore very valuable for the system design assessment of an actual system and the question of additional development work in the system design might be worth it or if a system change for further improvement would be a better strategy. In a privacy and security setting, the fundamental bounds describe what performances an adversary can achieve in the worst case. It therefore can be used to derive security or privacy guarantees which leads to security- or privacy-by-designs. Moreover, the proof of the fundamental bound often reveals what information-processing structure is the most promising strategy. It therefore often provides a deep understanding of information processing and guides towards efficient design structures. The results are often timeless and there are numerous interesting open problems that need to be solved.
In this project, we want to explore fundamental bounds for traditional communication scenarios, source coding setups, distributed-decision making, physical-layer security and privacy as well as statistical learning and data disclosure.
Background and summary of fellowship
One of the main causes of the insecurity of IT systems is complexity. For example, the Linux kernel has been designed to run on all possible platforms (including our IoT light bulb, the largest supercomputer, and the International Space Station) and includes all sorts of features to accommodate several usage scenarios. Even if the kernel is a foundational part of the majority of our software infrastructure and has been developed by high-quality engineers, this complexity results in 30 million lines of code that are virtually impossible to implement correctly. The kernel contains thousands of documented bugs and an unknown number of undiscovered issues. This leaves fertile ground for attackers that can steal our data, use our resources to mine bitcoins, or take complete control of our systems.
We believe that systems should be developed with much more rigorous techniques. We develop methods to mathematically model hardware and software systems and techniques to verify with mathematical precision the impossibility of vulnerabilities. Even if these techniques are heavy-duty, we focus our research on the analysis of the components that constitute the root of trust of the IT infrastructure, with the goal of demonstrating that faults of untrusted applications can be securely contained and that cannot affect the critical part of the system. That is, we do not aim to guarantee that PokenGo is bug-free, but we can mathematically rule out that its bugs can be used to steal your BankID or your crypto wallet. In particular, we are currently focusing on developing the theories to prevent recent famous vulnerabilities (e.g. Spectre) that are caused by low-level processor optimizations.
Background and summary of fellowship
Data has all the information, and efficient processing of data for information extraction is a key to achieving the right decision. Computers help to understand the data, extract important information and then finally provide a decision. Computers use a particular tool from the engineering field of computer science, called machine learning for realizing the help. The use of machine learning is growing, from speech recognition to robots to autonomous cars to medical fields including life science data analysis. Today machine learning is at the core of many intelligent systems across all science and engineering fields. Naturally, machine learning has to be highly reliable. Thanks to the Digital Futures fellowship, I am fortunate to address a challenge in modern machine learning. The challenge is how to make the machine learning fields more trustworthy and unbiased. For example, a visual camera-based face recognition system should not discriminate against people due to skin colour or gender.
Towards the challenge, a prime concern is to develop explainable machine learning (xML) systems, closely related to explainable artificial intelligence (xAI). Preferably, users should be able to understand what can be the precise effect or outcome of the systems before their formal use. Mistakes after formal use are costly in many situations, for example, detection of infection in a clinic/hospital. We should fully understand how computers use data for information extraction, and then reach a decision using the information. In turn, how computers can explain actions to users. The development of xML/xAI requires a confluence of mathematics, computer science and real-life understanding of applications scenarios including user perspectives.