
About the project
Objective
This project aims to study a dramatically different approach to software development of safety-critical systems. Specifically, the overall research goal is to: develop a new foundation for agile development of complex and regulated safety-critical cyber-physical systems that enable high-confidence rapid software development of systems with certification compliance requirements.
More specifically, we will address the following research challenges by:
- designing and evaluating a new agile development methodology for software and systems design for heavily regulated domains (specifically the defense industry), posing requirements on consistency between software implementation, design documentation, and compliance control according to certification authorities.
- developing new techniques, algorithms, and methods for supporting such new agile methodology, by designing new transformer-based optimization and verification techniques that are both sound and minimize false positives.
- constructing an interactive software prototype that can, in real-time, analyze software code and documentation, automatically perform compliance checks, and report live information on a dashboard available to the R&D organization.
Sweden’s defense industry’s competitiveness is vital for the safety and security of the country, where Saab AB is the major player. Two key components for competitiveness are development speed (short lead time) and flexibility (quickly adapting to changes). Both speed and flexibility are hampered by rigid processes: this project innovates in a dramatically different approach compared to current practices.

Background
Safety-critical cyber-physical systems—such as the modern aircraft fighters like Saab Gripen—are significantly relaying on software technology. Besides strong requirements of correctness and reliability, developing such systems falls under heavy regulation and certification control, including certification standards such as DO-178C. As a consequence, the development processes of such systems are extremely complex, requiring significant manual documentation, formal meetings, and control, which result in long development, innovation, and release cycles.
On the other hand, the development of non-safety critical software has, for several decades, been using agile methodologies (e.g., Scrum and Kanban) and quick iteration cycles. Moreover, the recent trend with generative AI tools based on LLMs and transformer technology, has paved the way for even more rapid development, using AI assisted pair programming systems such as GitHub Co-pilot, CodeWhisperer, and Codeium.
The key question addressed in this project is: how can agile development methodologies and assisting software tools be designed in the context of safety-critical systems with certification and regulation requirements? Specifically, the research problems concerns (i) soundness—how can we guarantee the correctness of analyses results, (ii) completeness—how can false positives be mitigated to make the system useful in practice, and (iii) explainability—how can analysis results be traced back to source data.
Crossdisciplinary collaboration
This project is conducted in close collaboration between the aerospace and defense company Saab AB and KTH Royal Institute of Technology.
Participating in the project:
- Main PI: David Broman, Professor, KTH Royal Institute of Technology
- Co-PI: Thomas Nordh, Product Owner and Business Area Leader, Saab AB
- Co-PI: Daniel Stensér, Digital Acceleration Officer, Saab AB
About the project
Objective
In this project we develop semantic tokenization models for sign language (SL), and combine these with large language models, leading to machine learning models that can understand, process, translate and generate SL efficiently. To achieve this, we will pool together large data resources, through our collaboration with SVT and other large-scale multilingual sign language datasets.
We will fine-tune and evaluate our models across a number of downstream tasks e.g., sign language recognition, segmentation, and production. The project addresses the need for inclusive and accessible urban infrastructures by reducing communication barriers for the deaf and signing communities, e.g. via automated translation and interpretation services that can enable seamless interaction between signers and non-signers, fostering integration in public services, workplaces, and social settings.
Background
Currently, we are seeing an AI-revolution fueled by large language models. What started out as text-only models has developed into generalized multimodal information processing frameworks, handling many languages, and different modalities such as images, speech and video, often with surprising accuracy.
Sign languages are visuo-spatial natural languages used by more than 70 million people world wide. Sign languages lack a text-based representation, and have not been part of, or benefited from, the large language model or foundation model developments. Furthermore, sign language technology is not being prioritized by the large corporate interests that are driving current AI developments.
Signed languages represent a special challenge since they, in contrast to spoken languages, have no universally adopted written form. For storage and transmission, one has to rely on video. For communication between signers and non-signers, either costly interpreter services are required, or one has to resort to limited text-based communication – which will be in a second language to a native signer. The promise and potential utility of sign language (SL) technology is thus substantial in terms of reducing communication barriers, allowing for signers to use language technology in their native language. Despite this, progress in SL technology has been limited in comparison to the rapid development for spoken languages. In this project we suggest an efficient way to allow sign language to inhabit the LLM ecosystem and benefit from the GPT-revolution.

Cross-disciplinary collaboration
The proposed project is a multidiciplinary endeavor. Advancing the state of the art in SL processing through foundation models requires combined expertise in machine learning, spoken language engineering, data processing and SL corpora and SL linguistics, including native sign-language users. The project team is composed to provide this expertise.
About the project
Objective
This research aims to create a strong framework for Online Continual Learning (OCL) that will help AI models learn gradually from streaming data. It will tackle the catastrophic forgetting phenomenon and maintain long-term flexibility, with a focus on high-stakes, changing environments where models need to adjust quickly without retraining. This is especially important in healthcare and other real-world areas where data changes constantly and unpredictably.
Background
Traditional AI models, especially in Deep Learning (DL), are usually trained on fixed datasets and used as set systems, making them fragile in changing situations. When new tasks or data come up, these models either need expensive retraining or risk forgetting what they previously learned. This inflexibility limits their growth and usefulness in real-world scenarios
Online continual learning changes this by allowing models to update continuously as new data comes in, much like how humans learn over time. However, this approach brings complex challenges, such as finding a balance between stability (keeping old knowledge) and plasticity (adjusting to new information).
Finding this balance in high-dimensional areas is particularly hard, as updates need to happen in real-time while following strict memory and processing limits. Take healthcare as an example: patient profiles and medical knowledge change every day. AI systems must keep up without sacrificing safety or accuracy. The implications go beyond healthcare. They also include autonomous systems that must navigate changing environments and adaptive vision models that need to stay relevant amid ever-changing data streams.
About the Digital Futures Postdoc Fellow
Romeo Lanzino is a researcher in Artificial Intelligence. He focuses on Computer Vision, Continual Learning, and , bioinformatics . He is currently a postdoctoral researcher at KTH Royal Institute of Technology, where he’s researching adaptive AI systems that can learn continuously from changing data streams. He earned a PhD in Artificial Intelligence at Sapienza University of Rome (Italy) under the Italian National PhD AI program. His doctoral research looked closely at how Deep Learning is used for analyzing physiological signals, questioning common beliefs about how well neural networks perform in Electroencephalography studies. He has a background in computer science from Sapienza, where he received both his BSc and MSc with honors. Romeo is active in the academic community as a reviewer for top venues like ICCV, NeurIPS, and IEEE Transactions on Multimedia, and he also co-organizes related workshops at major conferences.
Main supervisor
Atsuko Maki, KTH
Co-supervisor
Josephine Sullivan, KTH
About the project
Objective
This project aims to build mathematical foundations and design efficient algorithms for problems on metric graphs. The research will proceed in two stages. First, the focus will be on developing geometric and topological methods to construct or reconstruct metric graphs from real-world data. Second, the project will address the extraction of statistical information and the solution of applied problems on metric graphs through optimization-based approaches.
Background
Metric graphs offer a powerful way to model real-world data that has an underlying network structure together with spatial attributes. Examples of metric graphs include road networks, brain connectivity networks, and social networks. Unlike tabular data which is well-structured, metric graphs are inherently complex and nonlinear. Existing methods are ill-suited for computational and practical analysis of metric graphs, which limits their utility as models for real data. My research aims to provide an essential framework for applications of metric graphs in machine learning and data science.
About the Digital Futures Postdoc Fellow
Yueqi Cao completed his PhD in mathematics at Imperial College London in 2025. He works on applied and computational mathematics and statistics, with a particular interest in geometric and topological data analysis. Prior to that, he obtained master’s degree and bachelor’s degree in mathematics from Beijing Institute of Technology.
Main supervisor
Johan Karlsson
Co-supervisor
Sandra Di Rocco
About the project
Objective
This project aims to create a real-time digital twin framework enhanced with physics-informed neural networks (PINNs) to guide the development of plant-based meat analogs. By integrating mechanistic modeling with AI, the framework will provide deeper insight into protein structuring and deliver accurate, efficient tools for predicting and optimizing texture.
Background
Food production is a major driver of climate change, biodiversity loss, and public health challenges. While the transition to plant-based diets offers clear sustainability benefits, consumer acceptance is limited by the difficulty of reproducing the texture of meat. Current development approaches rely on costly, time-consuming trial-and-error experimentation. This project pioneers a systematic, data- and physics-driven strategy to accelerate texture design, reduce development costs, and enable more sustainable, nutritious, and appealing plant-based foods.
About the Digital Futures Postdoc Fellow
Jingnan Zhang holds a PhD in Food and Nutrition Science. Her research integrates computational modeling and soft matter physics with food science, enabling a systems-oriented approach to connect digital technologies with sustainable and resilient innovations for the future of food.
Main supervisor
Francisco Javier Vilaplana Domingo, Professor, Department of Chemistry, KTH Royal Institute of Technology.
Co-supervisor
Anna Hanner, Associate professor, Department of Fibre and Polymer Technology, KTH Royal Institute of Technology.
About the project
Objective
There are abundant unlabeled and noisy data in research fields of modern biology and medical science. Naturally, estimating biological structures and networks from unlabeled and noisy data widens the scope of future AI-based research in biology, with directly actionable effects in medical science. The major technical challenge is development of robust AI and GenAI methods that can use information hidden in unlabeled and noisy data. A promising path to address the challenge is to include a-priori biological knowledge in developing models for signals and systems, and collecting data, and then regularize the learning of AI methods.
In pursuit of addressing the challenge, we focus on inference of gene regulatory networks (GRNs) from their noisy gene expression level data – a challenging inverse problem in biology. Understanding and knowing a GRN is a key for understanding biological mechanisms causing diseases such as cancer. While gene expression data is available in abundance, the data is unlabeled due to absence of knowing the true GRNs underneath. In addition, the expression data is noisy. So far, use of AI for robust estimation of large-size GRNs from unlabeled and noisy gene expression level data has been little exercised. Indeed, learning from unlabeled and noise data is challenging for AI methods. Here comes the motivation for the proposed project – Biology-informed Robust AI (BRAI). The objective of the BRAI project is to develop fundamental theory and tools for inferring complex biological structures and networks from unlabeled and noisy data using a-priori biological knowledge, focusing on the challenging inverse problem ‘GRN inference’.
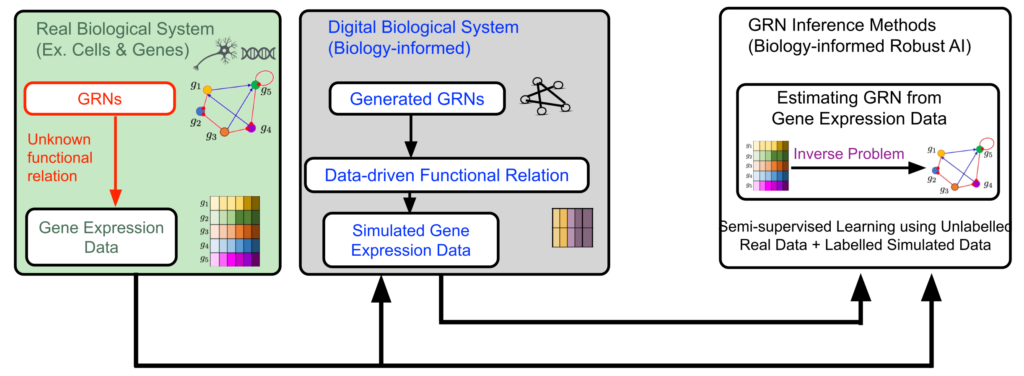
Background
The human reference genome contains somewhere between 19,000 – 20,000 protein-coding genes. For human cells (ex. cancer cells), GRNs are large. In reality, the GRNs are not observed directly. They are observed through the gene expression data. Therefore, it is difficult to collect labeled data as pairwise GRN- and -expression data for training AI and machine learning (ML) in a standard supervised learning approach. On the other hand, there are gene expression data available in abundance as unlabeled data, without the true GRNs underneath.
The actual functional relationship between a GRN matrix and its expression data is governed by complex biophysics. For complex biological systems like cancer cells, the true functional relationship governing GRN-to- expression data is unknown, and difficult to model. In addition, the gene expression data is noisy, as the expression data contains not only information from the hidden GRN, but other known-and-unknown biological events.
Naturally, the GRN inference problem – estimating a large GRN from its noisy gene expression data without having labeled data and knowing their actual functional relationship – is a challenging inverse problem.
Cross-disciplinary collaboration
The project will combine methods and techniques from separate research fields – (a) biological knowledge about GRNs from bioinformatics and system biology, (b) graph theory and topological data analysis for network modeling from mathematics, and (c) robust machine learning (ML) and GenAI from AI / ML.
About the project
Objective
This project aims to advance the understanding of flexible protein dynamics by developing novel algorithms that integrate cryo-electron microscopy (cryo-EM) data with computational predictions using generative AI and statistical modeling. The goal is to overcome current limitations in protein structure prediction by accurately reconstructing continuous, atomic-resolution 3D structures and their dynamic variations. Ultimately, the project will provide transformative tools for the global life sciences community, enhancing insights into molecular functions critical for health, biotechnology, and medicine while strengthening Sweden’s leadership in AI4Science.
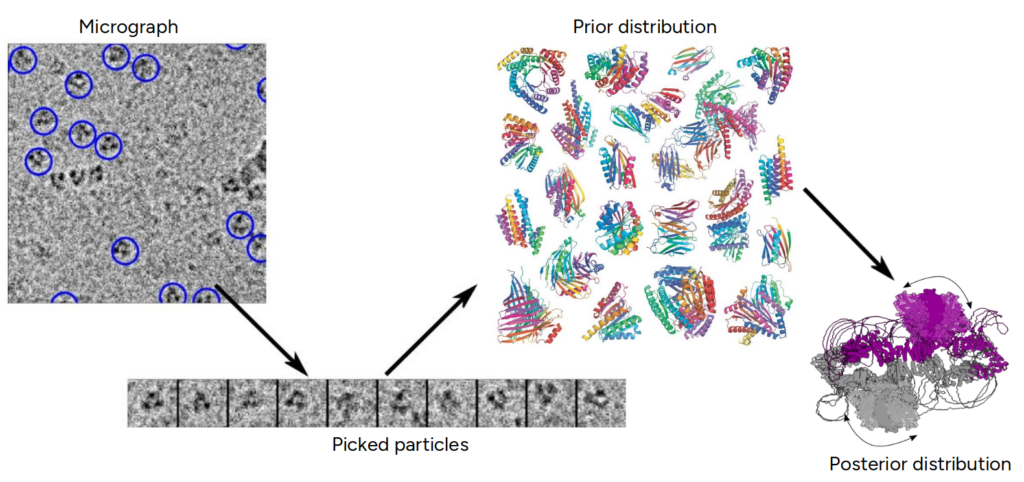
Background
Understanding the dynamic structures of flexible proteins is a major challenge in structural biology, as these molecules undergo continuous conformational changes essential for their biological functions. While cryo-electron microscopy (cryo-EM) has revolutionized the visualization of biomolecules at near-atomic resolution, capturing their full dynamic range remains difficult. Current computational methods, including AI-based predictions like AlphaFold, often fall short in modeling the continuous motions and heterogeneity of flexible proteins.
This project builds on advances in cryo-EM imaging, statistical modeling, and generative AI to develop new approaches that can more accurately reconstruct and analyze protein dynamics, addressing critical gaps in both experimental and computational techniques.
Cross-disciplinary collaboration
The project brings together experts from mathematics, machine learning, and structural biology to tackle complex challenges in biomolecular dynamics. Mathematicians contribute advanced statistical and inverse problem-solving techniques crucial for developing robust reconstruction algorithms. Machine learning specialists develop generative AI models to create data-driven priors that enhance the interpretation of cryo-EM data.
Finally, structural biologists provide essential expertise in cryo-EM methodologies, including sample preparation and image processing, ensuring high-quality experimental data, but more importantly provide critical domain expertise in order to design and evaluate the proposed methods.