
About the project
Objective
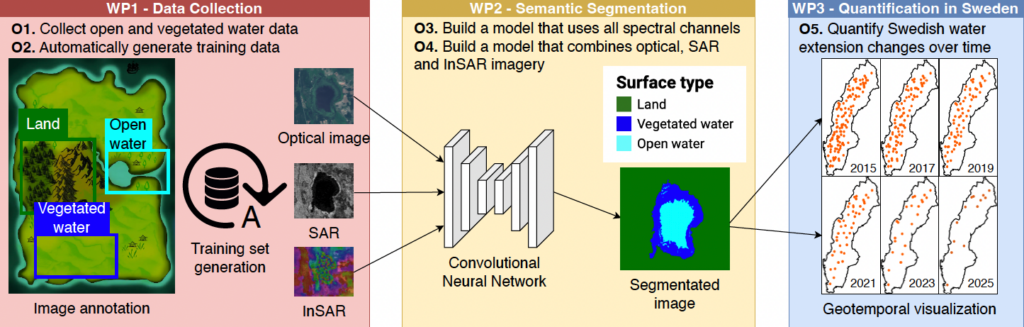
The main purpose of the DeepAqua project is to quantify the changes in surface water over time. We want to create a real-time monitoring system of changes in water bodies by combining remote sensing technologies, including optical and radar imagery, with deep learning techniques to perform computer vision and transfer learning. Employing this innovative strategy will allow us to calculate the water extent and level dynamics with unprecedented accuracy and response time speed. This approach offers a practical solution for monitoring water extent and level dynamics, making it highly adaptable and scalable for water conservation efforts.
Background
Climate change presents one of the most formidable challenges to humanity. In the current year, we have witnessed unprecedented heatwaves, extreme floods, an increasing scarcity of water in various regions, and a troubling surge in the global extinction of species. Halting the advance of climate change necessitates the preservation of our existing water resources. However, recent advancements in remote sensing technology have yielded a wealth of high-quality data, opening up new avenues for researchers to leverage deep learning (DL) techniques in water detection. DL is a machine learning methodology that consistently outperforms traditional approaches across diverse domains, including computer vision, object recognition, machine translation, and audio processing.
This project, named DeepAqua, seeks to enhance our understanding of surface water dynamics and their response to environmental changes by developing innovative DL architectures, such as Convolutional Neural Networks (CNN) and Transformers, designed specifically for the semantic segmentation of water-related images. It is worth noting that many DL models depend on substantial amounts of ground truth data, which can be costly to obtain. Our previous findings suggest that we can train a CNN using water masks based on the Normalized Difference Water Index (NDWI) to detect water in Synthetic Aperture Radar (SAR) imagery without the need for manual annotation. This breakthrough promises to have a significant impact on water monitoring since generating data based on NDWI masks is virtually cost-free compared to traditional methods involving fieldwork data collection and manual annotation.
Crossdisciplinary collaboration
The researchers in the team represent the Division for Water and Environmental Engineering (SEED/ABE), the Division of Software and Computer Systems (CS/EECS), KTH, and Stockholm University.
About the project
Objective
The project envisions a mobile cyber-physical system where people carrying mobile sensors (e.g., smartphones, smartcards) generate large amounts of trajectory data to sense and monitor human interactions with physical and social environments. The project aims to develop a causal artificial intelligence (AI) methodology to analyze and model human mobility behaviour dynamics (decision-making) using individual travel trajectory data and develop the causal diagrams of human mobility behaviour under disturbances that could help design effective strategies for sustainable and resilient urban mobility systems. The research challenges are learning the complex ‘hidden’ human decision-making mechanism from pervasive ‘observed’ trajectories and developing effective, scalable causal AI models and algorithms.
Background
The ever-changing mobility landscape and climate change continue challenging existing operating models and the responsiveness of city planners, policymakers, and regulators. City authorities have growing investment needs that require more focused operations and management strategies that align mobility portfolios to societal goals. The project targets the root cause of traffic (human) and novel analytic techniques to learn and predict human mobility behaviour dynamics from pervasive mobile sensing data that can help cities meet both sustainability challenges (through predicting congestion, emissions, and energy consumption) and improve urban resilience to disruptive events (such as infrastructure failures, natural disasters, or pandemics).
The human mobility area witnessed active developments in two broad but separate fields: transport and computer science. They work with different data, use different methods, and answer different but overlapping questions, i.e., mobility behaviour modelling using ‘small’ data in transport and mobility pattern analysis using ‘big’ data in computer science. A solid bridge between these is beneficial and needed but is still an open challenge. Mobile sensing and information technology have enabled us to collect much mobility trajectory data from human decision-makers. The predictive AI techniques show the potential to learn and predict human mobility using these trajectory data efficiently. However, they continually run up against the limits of what they observe (correlations, not causal relationships), thus hindering any serious applicability for preparedness and response policies for cities without understanding the causal mobility dynamics.
cAIMBER will bridge the two human mobility research streams in Transport Science and Computer Science. Also, it will develop the causal AI methodology, merging the RL and Causal Inference research fields. Integrating interdisciplinary expertise and techniques will derive generalizable insights about human behaviour dynamics that contribute to the scientific communities’ theoretical conceptualization of travel choices and decision-making mechanisms. Practically, cAIMBER conducts extensive empirical analysis using a comprehensive dataset covering different types of system disturbances for seven years. The accumulated knowledge of human mobility under these situational contexts would help city planners and service operators to make more informed decisions for sustainable and resilient travel.
Crossdisciplinary collaboration
The researchers in the team represent the KTH School of Architecture and Built Environment (ABE), Civil and Architectural Engineering Department, Transport Planning Division and KTH School of Engineering Science (SCI), Mathematics Department, Mathematics for Data and AI Division. Strategic research partners at KTH iMobility Lab and MIT Transit Lab support the project.
About the project
Objective
The aim of this project is to analyse and understand the environmental impacts of increased digitalisation and the use of Information and Communication Technologies (ICT) from a life cycle perspective. The project will include both method development and application through case studies. It will build on established life cycle assessment (LCA) approaches and further develop methods to estimate the environmental and resource impacts of both existing and future ICT systems and solutions. The assessments will address a broad spectrum of impacts, including climate change and energy use, but also other environmental and resource-related impacts.
The project will analyse not only the direct (first-order) environmental impacts of ICT, including those related to raw material extraction, production, use, and end-of-life treatment, but also indirect effects such as substitution and optimisation (second-order), as well as broader transformative and rebound effects (higher-order). Particular attention will be given to the enabling potential of digital solutions, meaning their ability to reduce environmental impacts in other sectors, and to identifying the conditions under which such benefits are achieved or undermined by unintended consequences.
Several methodological challenges will be addressed in this project. These include the development of simplified LCA methods suitable for use in product development and design, prospective LCA approaches to evaluate potential impacts of future systems, and the inclusion of broader environmental and resource indicators. The project will also assess how digitalisation affects consumption patterns and explore the environmental implications of those changes. Case studies may vary in scale, focusing on specific devices, applications, and broader sectoral or societal assessments.
Background
The ICT sector is currently responsible for an estimated 1.4 percent of global greenhouse gas emissions (Malmodin et al. 2024). While the future size of this footprint is uncertain, digitalisation is also regarded as a key enabler of sustainability through improved efficiency, reduced material consumption, and the introduction of new low-carbon solutions. This dual role presents both opportunities and risks, making it essential to apply robust and scientifically grounded methods for evaluating environmental consequences.
The environmental effects of digitalisation can be categorised into direct effects such as emissions and resource use during production, use and disposal, second-order impacts (substitution and optimisation effects that occur when digital systems replace traditional ones), and higher-order impacts (including systemic changes such as rebound and induction effects, as well as positive effects like encouraging sustainable lifestyles). A comprehensive understanding of these effects is necessary for sound decision-making and policy formulation.
Life cycle assessment (LCA) is a widely accepted and standardised method for assessing environmental and resource impacts throughout the life cycle of a product, service, or system, from raw material extraction to end-of-life management. This methodology will be used to evaluate both direct and indirect impacts of ICT.
This project will advance LCA methodologies and provide improved tools for assessing how digitalisation influences environmental sustainability. The collaboration between KTH and Ericsson builds on ongoing joint efforts and aims to strengthen the knowledge base and academic ecosystem in the Stockholm region. Outcomes from the project will contribute to both research and education, supporting science-based evaluations of digital solutions and their alignment with climate and environmental goals.
Cross-disciplinary collaboration
This project is inherently cross-disciplinary, as it brings together expertise from environmental sciences, engineering, digital technologies, futures studies, and industrial practice to address the complex interplay between digitalisation and sustainability. Understanding the environmental life cycle impacts of ICT systems requires not only advanced methodological knowledge in life cycle assessment (LCA), but also technical understanding of digital technologies, insights into social and behavioural change, and practical perspectives from industry.
This cross-disciplinary setup also extends to the societal dimension of the project. The analysis of consumption patterns, substitution effects, and rebound phenomena requires insights from social sciences and sustainability transitions research. By integrating these perspectives with engineering and environmental science approaches, the project aims to provide a more holistic understanding of the environmental impacts of digitalisation.
PI
Göran Finnveden is a Professor of Environmental Strategic Analysis at the Department of Sustainable Development, Environmental Sciences and Engineering at KTH. He is also the director of the Mistra Sustainable Consumption research program. His research is focused on sustainable consumption and life cycle assessment, and other sustainability assessment tools. The research includes method development and case studies in different areas, including the environmental impacts of ICT. He is the PI of this project.
Co-PIs
Mattias Höjer is a Professor and an expert in environmental strategies and futures studies at KTH Royal Institute of Technology in Stockholm, Sweden. He has been a professor since 2012 and is affiliated with the Department of Sustainable Development, Environmental Science and Engineering (SEED), as well as KTH Digital Futures and the KTH Climate Action Centre. His research encompasses smart sustainable cities, digitalization, energy use, climate change mitigation, and the development of futures studies methodologies. He has a particular interest in how digital technologies can support sustainability transitions in urban environments. He is a co-PI of this project.
Jens Malmodin is a Senior Specialist in Environmental Impacts and LCA at Ericsson and has over 30 years of experience in energy-efficient design, life cycle assessment (LCA), environmental assessments, and environmental data reporting. He has published numerous papers and articles on the LCA of ICT products, systems, and services, including studies of the energy and carbon footprint of the ICT sector and how ICT can help society reduce its environmental impact. Jens holds an M.Sc. in material engineering from the Royal Institute of Technology (KTH), Stockholm, Sweden. He is a co-PI of this project.
Partners
Shaoib Azizi has the experience of working in the industry on large-scale refrigeration and heat pump systems and as an entrepreneur with solar pumps. His PhD at Umeå University included research on the opportunities for digital tools to improve buiding management and energy efficiency. He defended his thesis “A multi-method Assessment to Support Energy Efficiency Decisions in Existing Residential and Academic Buildings” in September 2021. Shoaib became a Digital Futures Postdoc researcher in digitalization and climate impacts at the Department of Sustainable Development, Environmental Science and Engineering (SEED) at KTH working on lifecycle assessment methodology to understand various aspects of digitalization and its impacts on the environment. He continues, as a researcher, to work in this research area, building on the knowledge and experience gained from the previous project as part of his current research initiatives.
Anna Furberg defended her PhD thesis in 2020 at Chalmers University of Technology. Her thesis, titled “Environmental, Resource and Health Assessments of Hard Materials and Material Substitution: The Cases of Cemented Carbide and Polycrystalline Diamond”, involved Life Cycle Assessment (LCA) case studies and method development. After her thesis, she worked at the Norwegian Institute for Sustainability Research, NORSUS, on various LCA projects and, in several cases, as the project leader. In 2022, she was awarded the SETAC Europe Young Scientist Life Cycle Assessment Award, which recognizes exceptional achievements by a young scientist in the field of LCA. Anna became a Digital Futures Postdoc in digitalization and climate impacts at the Department of Sustainable Development, Environmental Science and Engineering (SEED) at KTH in 2023. She continues working in this area now employed as a researcher at SEED, focusing on environmental impacts of ICT with the aim to contribute with increased knowledge about potential current and future impacts of digitalization.
Nina Lövehagen joined Ericsson Research in 2000 and works as a Master Researcher focusing on the climate impacts of ICT. Her work involves understanding the energy use and greenhouse gas emissions of the ICT sector, developing methodologies to assess the enablement effect of ICT in other sectors, and creating simplified methodologies to understand the full environmental footprint of ICT. She is also active in the International Telecommunication Standardization (ITU). Nina holds an M.Sc. in electrical engineering from the Royal Institute of Technology (KTH), Stockholm, Sweden.
About the project
Objective
People with autism are a large group at Day Activity Centers, and autism is one the most common neurodevelopment diagnoses that can imply severe disability for many people. The Platform for Smart People (PSP): Understanding Inclusion Challenges to Design and Develop an Independent Living Platform in a Smart Society for and with people with autism project is about creating a platform to make people with autism more independent of help from others in everyday life situations. The focus is on real-life challenges and opportunities at Day Activity Centers.
This will be achieved by co-designing and developing a Platform for Smart People. The platform will include an accessible Augmented Reality app with a Machine Learning framework and Civic Intelligence to advance the current state-of-the-art digitalisation and smart society for people with autism. An iterative co-design process will ensure that requirements for people with autism are met in the platform.
Background
People on the autism spectrum present a particular challenge. Tasks that neurotypical people take for granted to do easily (e.g. planning a day) may be out of the abilities of people with autism who still must live independently and work. To overcome these barriers, there are potential opportunities based on current research and development.
Augmented Reality means that the actual world is augmented with digital objects (graphics, audio, haptics) by detecting actual-world objects, tracking positions, sensing distance and depth, and integrating light settings. Previous research shows the feasibility of using Augmented Reality to help autistic people with social communication skills and independent living tasks.
Machine Learning is a tool that can automate tasks to make the augmented world more accessible, such as identifying real-world objects. However, Machine Learning has a so-called cold-start problem where big data sets are needed to make it useful. To overcome this, a Civic Intelligence component is needed, where staff at Day Activity Centers can contribute with individual adaptations that they know work for each person. The results can have a wide outreach by combining the advances above and integrating them with the Global Public Inclusive Infrastructure research efforts.
Crossdisciplinary collaboration
The partnership is composed of a multidisciplinary team to respond to the corresponding cross-disciplinary responses required of the project. The researchers in the team represent the Department of Computer and Systems Sciences at Stockholm University (SU), the Department of Special Education at SU, and KTH. In addition, several Day Activity Centers in Stockholm are involved. The project Advisory Board consists of representatives from Autism och Aspergerförbundet, Rinkeby-Kista Day Activity Center, IBM, Trace R&D Center and Raising the Floor.
Background and summary of fellowship
Power electronics technology enables efficient electricity usage by controlling electronic devices with digital algorithms. The software-controlled, power-electronic converters have been vastly used in modern society and become a transformational technology for the energy transition. The proliferation of power-electronic converters transforms legacy energy systems with more flexibility and improved efficiency, yet it also brings new security challenges to energy systems. In recent years, power disruptions induced by erratic interactions of converter-based energy assets have been increasingly reported. Methods for the dynamics analysis of power electronic systems are urgently needed to screen instability and security risks in modern energy systems.
This project aims to leverage digital technologies to redefine the paradigm of dynamics analysis for power electronic systems. First, a trustworthy artificial intelligence (AI) modelling framework for converter-based energy assets will be established. Physical-domain knowledge will be combined with the recent advances in machine learning algorithms to make the AI model more reliable. Then, based on the AI models of power converters, a scalable and efficient dynamics analysis approach will be developed for power electronic systems, ranging from single converters to hundreds of thousands of converters. Finally, physics-based models of benchmark energy systems will be built to test the effectiveness of developed models and methods.
Research in the area of power electronics-controlled power systems. Wang is active in the broader community working in the area and will bring further visibility and provide strong leadership.
Xiongfei Wang has been a Professor with the Division of Electric Power and Energy Systems at KTH Royal Institute of Technology since 2022. From 2009 to 2022, he was with the Department of Energy Technology, Aalborg University, where he became an Assistant Professor in 2014, an Associate Professor in 20
Background and summary of fellowship
Fundamental bounds of information processing systems provide the limit on theoretically possible achievable performances. For instance, in communications, the information-theoretic Shannon capacity describes the fundamental bound on what communication rate can be maximally achieved with vanishing error probability. This fundamental bound can be then used as a benchmark for the actual system design. It is therefore very valuable for the system design assessment of an actual system and the question of additional development work in the system design might be worth it or if a system change for further improvement would be a better strategy. In a privacy and security setting, the fundamental bounds describe what performances an adversary can achieve in the worst case. It therefore can be used to derive security or privacy guarantees which leads to security- or privacy-by-designs. Moreover, the proof of the fundamental bound often reveals what information-processing structure is the most promising strategy. It therefore often provides a deep understanding of information processing and guides towards efficient design structures. The results are often timeless and there are numerous interesting open problems that need to be solved.
In this project, we want to explore fundamental bounds for traditional communication scenarios, source coding setups, distributed-decision making, physical-layer security and privacy as well as statistical learning and data disclosure.
Background and summary of fellowship
One of the main causes of the insecurity of IT systems is complexity. For example, the Linux kernel has been designed to run on all possible platforms (including our IoT light bulb, the largest supercomputer, and the International Space Station) and includes all sorts of features to accommodate several usage scenarios. Even if the kernel is a foundational part of the majority of our software infrastructure and has been developed by high-quality engineers, this complexity results in 30 million lines of code that are virtually impossible to implement correctly. The kernel contains thousands of documented bugs and an unknown number of undiscovered issues. This leaves fertile ground for attackers that can steal our data, use our resources to mine bitcoins, or take complete control of our systems.
We believe that systems should be developed with much more rigorous techniques. We develop methods to mathematically model hardware and software systems and techniques to verify with mathematical precision the impossibility of vulnerabilities. Even if these techniques are heavy-duty, we focus our research on the analysis of the components that constitute the root of trust of the IT infrastructure, with the goal of demonstrating that faults of untrusted applications can be securely contained and that cannot affect the critical part of the system. That is, we do not aim to guarantee that PokenGo is bug-free, but we can mathematically rule out that its bugs can be used to steal your BankID or your crypto wallet. In particular, we are currently focusing on developing the theories to prevent recent famous vulnerabilities (e.g. Spectre) that are caused by low-level processor optimizations.