
About the project
Objective
Based on empirical data from sidewalk robots’ trips, we will shed light on sidewalk mobility and improve real-world robot delivery operations. Through statistical analysis and Machine Learning (ML), we will assess the efficiency of robots’ paths and their relation to pedestrian infrastructure, interactions with different transport users (such as walkers, cyclists, e-scooters, and motorized vehicles), and other variables (e.g., weather).
A crucial task of the project will focus on integrating prediction models with routing algorithms to discover more effective routing solutions. Another task will involve identifying Walkability KPIs” to describe sidewalk mobility conditions based on the data collected.
Background
Sidewalk robots appear to be a promising solution for City Logistics. Hubs, retail locations, and even retrofitted vehicles might dispatch them for short-range trips and partially replace standard, less sustainable delivery methods. The ISMIR project aims to develop a more comprehensive understanding of sidewalk robot delivery in realistic scenarios. The investigation of sidewalk navigation challenges will also provide the opportunity to explore pedestrian infrastructure and sidewalk mobility from a novel perspective.
Crossdisciplinary collaboration
The researchers in the team represent the KTH School of Architecture and the Built Environment, Department of Urban Planning & Environment, and KTH School of Electrical Engineering and Computer Science, Department of Intelligent Systems.
About the project
Objective
This project aims to support planning for universal access to clean cooking and contribute to Sustainable Development Goal 7 (SDG7) on Affordable and Clean Energy by radically integrating artificial intelligence (AI) methods into the open-source geospatial clean cooking model OnStove. To enhance OnStove, the project proposes implementing geospatial AI learning models to improve the spatial understanding of current technologies used for cooking and generate quasi-optimal transitions over an extended modelling period, considering as well behavioural issues. To achieve this, open-access geospatial information is combined with ground information gathered through available survey data. Finally, all comes together as a new open-source, user-friendly interface that will enable a broader audience to use the tool and ensure a long-term community of practice around clean cooking access modelling.
Background
Approximately 2.3 billion people still lack access to clean cooking worldwide, making them rely on traditional and polluting fuels. This practice poses challenges as households spend significant time collecting and cooking with traditional fuels, impacting women and children. Cooking with polluting fuels causes severe health consequences, estimated at around 3.2 million premature deaths annually from respiratory diseases. Moreover, traditional cooking exacerbates climate change and causes deforestation around the globe. On previous efforts, the first open-source geospatial tool for assessing and comparing the net benefits of various cooking solutions, OnStove, was developed. The tool was applied in the first study for sub-Saharan African countries, using Geospatial Information Systems (GIS) to evaluate cleaner cooking solutions in each square kilometre of the region. The tool considers benefits such as reduced morbidity, mortality, greenhouse gas (GHG) emissions, and time saved while factoring in investment costs, fuel purchase, and operation and maintenance.
By calculating the relative differences between current fuel stoves used and cleaner alternatives, OnStove determines a transition’s net benefit (benefits minus costs) and selects the options providing the highest net benefit in each square kilometre. Decision-makers can use the outputs to understand the impacts of achieving clean cooking access, including estimates on deaths avoided, time saved, GHG emissions avoided, health and GHG emissions costs avoided, total costs, and affordability constraints. OnStove facilitates decision-makers in identifying areas for action, guiding market strategies, and prioritizing investments to promote diverse clean-stove options in low- and middle-income countries. The tool has gained policy community interest, aiding energy access planning in Nepal and Kenya. It is also integrated into global initiatives like the World Resources Institute’s Energy Access Explorer and the International Energy Agency’s Clean Cooking Outlook Special Report.
Crossdisciplinary collaboration
Our project benefits from the expertise of a diverse team from the Department of Energy Technology and the Department of Sustainable Development, Environmental Science and Engineering at KTH Royal Institute of Technology. Furthermore, we collaborate closely with international organizations active in the clean cooking domain, such as the Clean Cooking Alliance (CCA), the World Resources Institute, The International Energy Agency, and Sustainable Energy for All. This expert group ensures that we have the technical and practical background to develop an innovative solution that addresses the project’s challenges and supports achieving SDG7’s clean cooking goals.
About the project
Objective
We propose energy-efficient, high-speed, real-time monitoring of complex traffic scenarios in urban areas. Reliable real-time information about urban traffic supports emergency responders and city planners and reduces carbon emissions, thereby increasing the urban citizens’ quality of life. Using decentralized neuromorphic sensing and processing, we obtain four benefits compared to state-of-the-art: (1) low latency, (2) minimal transmission bandwidth, (3) low power, and (4) enhanced privacy.
As a result of the project, we expect to provide a Live Demonstrator which, in real-time, identifies objects in traffic (e.g., cars, bicycles, and scooters) while continuously running on a negligible energy budget (e.g., a solar cell).
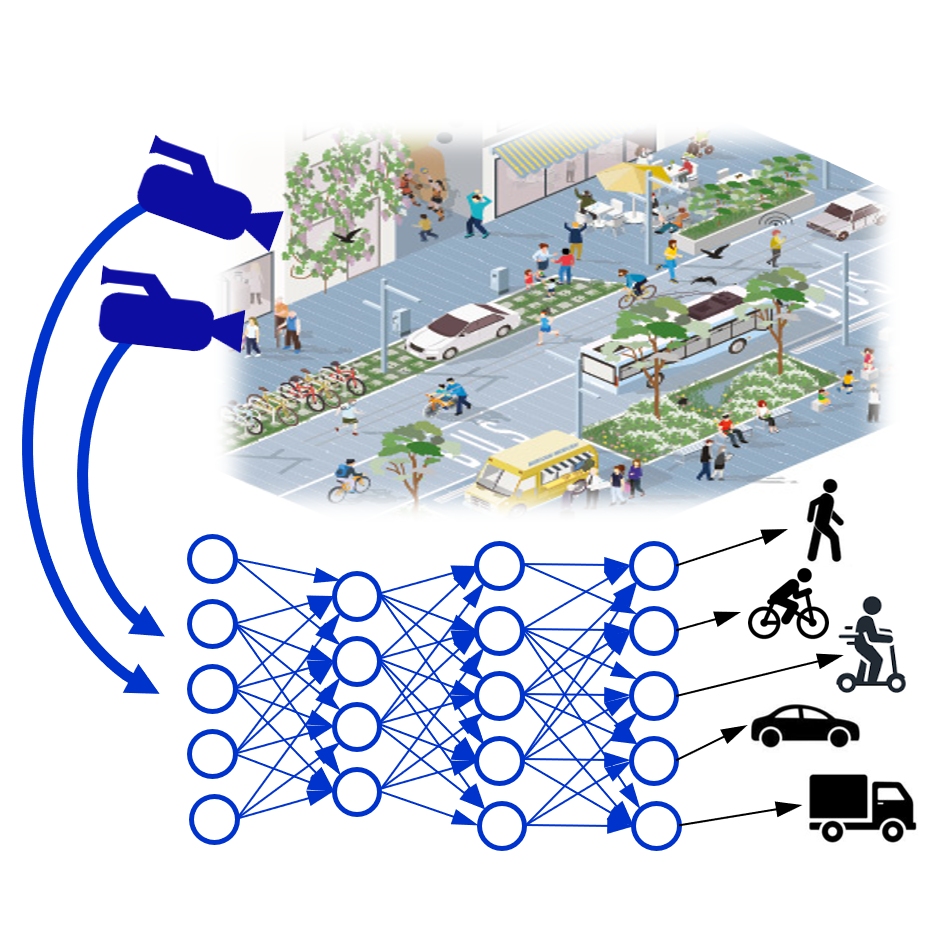
Background
In the upcoming decades, urban areas will become “much larger, more complex, and interconnected, ” requiring optimized infrastructure with increasing automatization at increasingly larger scales. More broadly, real-time information about traffic and infrastructure utilization will become an increasingly valuable commodity for companies and officials to adapt and update the infrastructure as needed. Such data is generated by video cameras in cities today.
Embedding low-power event cameras with low-power neuromorphic local computation provides a uniquely scalable solution for the growing need to monitor urban traffic and resource flows in real time. Our project estimates a 100x reduction in power and a 20x reduction in installation cost.
Crossdisciplinary collaboration
The teams contribute expertise in neuromorphic hardware and algorithms for system development and expertise in traffic observation and urban traffic management. Only both teams and their complementary expertise can develop real-time low-power computing systems for the societal relevant task of urban traffic monitoring.
About the project
Objective
- Develop the software and systems required for automated vehicle trials and representative demonstrations on KTH campus roads,
- Obtain approval from the Swedish Transport Agency for public road trials on the KTH campus with plans to expand the operational design domain gradually,
- Provide open data from on-vehicle and roadside sensors in a GDPR and data act-compliant way to foster open science and
- Enhance and mature open-source toolchains to support demonstrations and research, addressing safety and adversarial attacks on situational awareness of autonomous vehicles and their countermeasures.
Background
Despite the enormous investments in automated vehicles, there are still challenges regarding safety and security. Moreover, open research testbeds are lacking to address these challenges. The CAVeaT project will address those needs.
The project will leverage advances and resources made available from industrial partners, from the TECoSA edge-computing and 5G testbed, and from the ITM and EECS schools at KTH, including the AD-EYE platform and an adversarial attack pipeline for autonomous driving simulation.
Crossdisciplinary collaboration
The researchers in the team represent the KTH School of Industrial Engineering and Management and the KTH School of Electrical Engineering and Computer Science.
About the project
Objective
By delivering reliable, local and nearly real-time data about wildlife, the data gathered by FLOX Robotics drones provide insights for data-based wildlife-related decisions to veterinary institutes, nature conservationists, hunting associations, insurance companies and many others. Through AI-assisted identification of wildlife species, the stakeholders have the possibility to track the animal species which are injured, bearing diseases or have been involved in an incident.
The project demonstrates an integrated solution for automated mapping, identification, tracking and, when required, repelling wild animals using autonomous drones with AI-assisted computer vision and ultrasound repellent technology combined with a geographic information system (GIS)-like for data visualization, analysis and decision making.
Background
The problem of wildlife damage is widespread all over the world, from Sweden to Italy, in the US, India and many other countries. Historically, there has been limited means for quantifying the wild animal population, their moving patterns, and the damages they cause. Damage by wild animals to cultivated fields is a major cause of profit loss for farmers in Europe. In Sweden, in 2020, damage caused by wildlife occurred on 17% of the cultivated area for cereals and nearly 28% for starch potatoes. Temporary grasses are Sweden’s largest crop in acreage, and 17% of the cultivated area had some form of wildlife damage in 2020 [www.scb.se]. In Sweden, around 50% of agricultural companies reported damage from the wildstock in 2020, and more than one-third of farmers stated that the wildstock affects their choice of crops.
Wildlife-related damages are widely present not only in agriculture but also in forest areas. The “rooting” and “wallowing” by wild boars also has an environmental impact, destroying vegetation and degrading water quality. For wildlife-related insurance cases, there is often no physical evidence of species involved in the damage. The verification requires too high a burden of proof to be met to receive payments.
The project demonstrates an integrated solution for mapping and, when required, repelling wild animals using autonomous drones with AI-assisted computer vision and ultrasound repellent technology combined with a geographic information system-like (GIS) for data visualization, analysis and decision making. The project solution will help public authorities and decision making bodies to access site-specific identification of wildlife in larger areas, aggregated from separate fields to regional, national and even international levels.
Crossdisciplinary collaboration
The researchers in the team represent RISE Digital Systems and the Department of Computer and System Sciences at Stockholm University.
About the project
Objective
In the DataLEASH project, practically, we develop and test machine learning models, among other methods, to ensure the use of data without the risk of revealing people’s identities or allowing unwanted inferences about them. In a more theoretical approach, we aim at provable guarantees for privacy and take a holistic approach to the legal implications. This implies a quest for finding relevant rules and regulations and illuminating interpretation and application.
The project consortium from KTH, SU, and RISE has a unique set-up in terms of an interdisciplinary and multidisciplinary profile among the researchers, combining perspectives from information theory, legal informatics, language processing, machine learning, cryptography, and systems security.
Background
Digitalization has resulted in more and more data being generated and collected from various sources (such as health care, customer service, surveillance cameras, etc.). The data is valuable for processing and additional analysis to improve predictions and planning. Advances in machine learning have improved this kind of data analysis, while data-protection regulation such as the GDPR has introduced constraints, limiting what data can be used and for what purpose. There is, thus a tension between the utility of data and the privacy of the individuals the data is about.
Cross-disciplinary collaboration
DataLEASH brings together researchers from the School of Electrical Engineering and Computer Science (EECS, KTH), the Department of Computer and Systems Sciences (DSV) and the Department of Law both at Stockholm University and from the Decisions, Network, and Analytics lab at RISE.
Activities & Results
Activities, awards, and other outputs
- Speakers at workshops on “AI inom medicinteknik,” session “Vad minns en högparametriserad modell? Organized by Läkemedelsverket, April 6, online with more than 150 participants from industry and regulatory bodies.
- “Tillgängliggörande av hälsodata,” Dec 2021 online with more than 50 participants from four regions participating
- “Digital innovation i samverkan stad, region och akademi,” Oct 2021 online with about 20 participants from KTH, Region and City of Stockholm, plus some KTH internal events.
- Organisation and participation of panel at Nordic Privacy Forum 2022 panel discussing calculated privacy and the interplay between law and tech.
- DataLEASH organizes regular seminars every two months for three years with the City of Stockholm and Region Stockholm about requirements from the stakeholders and the results from our research project.
- SAIS 2022, Swedish AI Society workshop, is organised and paper [BFLSSR22] is presented in this workshop.
- Award: Rise solution for Encrypted Health AI was announced the winner of the Vinnova Vinter competition in the infrastructure category.
Results
Research objectives of DataLEASH are: (i) develop and study privacy measures suitable for privacy risk assessment and utility optimization; (ii) characterization of fundamental bounds on data disclosure mechanisms; (iii) design and study of efficient data disclosure mechanisms with privacy guarantees; (iv) demonstration and testing of algorithms using real-data repositories; (v) study of the cross-disciplinary privacy aspects between law and information technology.
Research achievements and main results of DataLEASH:
- Pointwise Maximal Leakage (PML) has been proposed as a new privacy measure framework. PML has an operational meaning and is robust. Using the framework, several other privacy measures have been derived and their properties have been characterized as well as the relation to existing privacy measures have been established.
- The privacy-preserving learning mechanism PATE has been studied using conditional maximal leakage explaining the cost of privacy. PATE approach has been extended to deal with high-dimensional targets such as in segmentation tasks of MRI brain scans.
- Fundamental bounds on data disclosure mechanisms have been derived considering various pointwise privacy measures. Furthermore, approximate solutions to optimal data disclosure mechanisms have been derived using concepts from Euclidian Information Theory.
- In a cross-disciplinary study between law and tech, we propose and discuss how to relate the legal data protection principles of data minimization to the mathematical concept of a sufficient statistic to be able to deal from a regulatory perspective with the rapid advancements in machine learning.
- Health Bank, a large health data repository of 2 million patient record texts in Swedish has been de-identified. A deep learning BERT model, SweDeClin-BERT, has been created and obtained permission from the Swedish Ethical Review Authority to be shared among academic users. The model SweDeClin-BERT has been used at the University Hospital of Linköping with promising results. Handling sensitive health-related data is often challenging. Proposed Fully Homomorphic Encryption (FHE) to encrypt diabetes data. The proposed approach won the pilot Winter competition 2021–22 organized by Vinnova.
- We created a systematization of knowledge on ambient assisted living (combining the challenges of mobile and smart-home monitoring for health) from a privacy perspective to map out potential issues and intervention points.
- Using a cryptographic approach, we developed distance-bounding attribute-based credentials, which provide anonymity for location-based services, provably resisting attacks.
- We investigated the uses and limitations of synthetic data as a privacy-preservation mechanism. For image data, we developed a framework of clustering and synthesizing facial images for privacy-preserving data analysis with privacy guarantees from k-anonymity and found trade-off choice points with analysis utility. In a different work on facial images, we proposed a novel approach for the privacy preservation of attributes using adversarial representation learning. This work removes the sensitive facial expressions and replaces them with an independent random expression while preserving facial features. For tabular data, we investigated across several datasets whether different methods of generating fully synthetic data vary in their utility a priori (when the specific analyses to be performed on the data are not known yet), how closely their results conform to analyses on original data a posteriori, and whether these two effects are correlated. We found classification tasks when using synthetic data for training machine-learning models more promising in terms of consistent accuracy than statistical analysis.
In the interplay between information technology and law, the project itself has been a testbed, given the personal data processing in research of this kind. Quite often, there is a challenge merely to find the governing legal framework. Practical experiences and theoretical studies can be a sign of this. However, much research today is concentrated on specific data protection regulations. The reasoning above boils down to a broadened approach to GDPR.
Publications
We like to inspire and share interesting knowledge…
- Vakili, T., Hullmann T., Henriksson A. and H. Dalianis. 2024. When Is a Name Sensitive? Eponyms in Clinical Text and Implications for De-Identification. To be presented at the CALD-pseudo Workshop at the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024, Malta.
- Ngo, P., Tejedor M., Olsen Svenning T., Chomutare T., Budrionis A. and H. Dalianis. 2024. Deidentifying a Norwegian clinical corpus – An effort to create a privacy-preserving Norwegian large clinical language model. To be presented at the CALD-pseudo Workshop at the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024, Malta.
- Lamproudis, A., Mora, S., Olsen Svenning T., Torsvik T., Chomutare T., Dinh Ngo P. and H. Dalianis. 2023. De-identifying Norwegian Clinical Text using Resources from Swedish and Danish. Proceedings of AMIA 2023, Annual Symposium, November 11-15. New Orleans, LA, USA, link.
- Vakili, T. and H. Dalianis. 2023. Using Membership Inference Attacks to Evaluate Privacy-Preserving Language Modeling Fails for Pseudonymizing Data. Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa 2023). Faroe Islands, May 22-24, 2023, link.
- Vakili, T., Lamproudis, A., Henriksson, A. and H. Dalianis. 2022. Downstream Task Performance of BERT Models Pre-Trained Using Automatically De-Identified Clinical Data. In the Proceedings of the 13th International Conference on Language Resources and Evaluation, LREC 2022, Marseille, France, pp. 4245–4252, link.
- Vakili, T. and H. Dalianis 2022, Utility Preservation of Clinical Text After De-Identification. In the Proceedings of the 21st Workshop on Biomedical Language Processing (pp. 383-388) in conjunction with ACL 2022, Dublin, Ireland, link.
- Sara Saeidian, Giulia Cervia, Tobias J. Oechtering, Mikael Skoglund, Quantifying Membership Privacy via Information Leakage, IEEE Transactions Information Forensics and Security. Vol.16, pp. 3096-3108, 2021, link.
- Sara Saeidian, Giulia Cervia, Tobias J. Oechtering, Mikael Skoglund, Optimal Maximal Leakage-Distortion Tradeoff. Information Theory Workshop (ITW) 2021 IEEE, pp. 1-6, 2021, link.
- Vakili, T. and H. Dalianis. 2021. Are Clinical BERT Models Privacy-Preserving? The Difficulty of Extracting Patient-Condition Associations. In the Proceedings of the Association for the Advancement of Artificial Intelligence AAAI Fall 2021 Symposium in HUman partnership with Medical Artificial iNtelligence (HUMAN.AI), November 4-6, 2021, pdf.
- Lamproudis, A., Henriksson, A. and H. Dalianis. 2021. Developing a Clinical Language Model for Swedish: Continued Pretraining of Generic BERT with In-Domain Data. In the Proceeding of RANLP 21: Recent Advances in Natural Language Processing, 1-3 Sept 2021, Varna, Bulgaria, pdf.
- Grancharova, M. and H. Dalianis. 2021. Applying and Sharing pre-trained BERT-models for Named Entity Recognition and Classification in Swedish Electronic Patient Records. In the Proceedings of the 23rd Nordic Conference on Computational Linguistics, NoDaLiDa 2021, Iceland, May 31 – June 2, 2021, pdf.
- Dalianis, H. and H. Berg. 2021. HB Deid – HB De-identification tool demonstrator. In the Proceedings of the 23rd Nordic Conference on Computational Linguistics, NoDaLiDa 2021, Iceland, May 31 – June 2, 2021, pdf.
- Berg, H., Henriksson, A., Fors, U. and H. Dalianis. 2021. De-identification of Clinical Text for Secondary Use: Research Issues. In the proceedings of HEALTHINF 2021, 14th International Conference on Health Informatics Feb 11-13, 2021, pdf.
- Grancharova, M., Berg, H. and H. Dalianis. 2020. Improving Named Entity Recognition and Classification in Class Imbalanced Swedish Electronic Patient Records through Resampling. Compilation of abstracts in The Eight Swedish Language Technology Conference (SLTC-2020), Göteborg, pdf.
- Berg, H., A.Henriksson and H. Dalianis. 2020. The Impact of De-identification on Downstream Named Entity Recognition in Clinical Text. In Proceedings of the 11th International Workshop on Health Text Mining and Information Analysis, Louhi 2020, in conjunction with EMNLP 2020, (pp. 1-11), pdf.
- Berg, H., Henriksson, A., Fors, U. and H. Dalianis. De-identification of Clinical Text for Secondary Use: Research Issues. Presented at the Healthcare Text Analytics Conference HealTAC 2020, April 23, London.
- Berg, H. and H. Dalianis. 2020. A Semi-supervised Approach for De-identification of Swedish Clinical Text. Proceedings of 12th Conference on Language Resources and Evaluation, LREC 2020, May 13-15, Marseille, pp. 4444‑4450, pdf.
- Berg, H., T. Chomutare and H. Dalianis. 2019. Building a De-identification System for Real Swedish Clinical Text Using Pseudonymised Clinical Text. In the Proceedings of the Tenth International Workshop on Health Text Mining and Information Analysis, Louhi 2019, in conjunction with Conference on Empirical Methods in Natural Language Processing, (EMNLP) November 2019, Hongkong, ACL, pp 118-125, pdf.
- Berg, H. and H. Dalianis. 2019. Augmenting a De-identification System for Swedish Clinical Text Using Open Resources (and Deep learning). In the Proceedings of the Workshop on NLP and Pseudonymisation, in conjunction with the 22nd Nordic Conference on Computational Linguistics (NoDaLiDa), Turku, Finland, September 30, 2019, pdf.
- Dalianis, H. 2019. Pseudonymisation of Swedish Electronic Patient Records Using a Rule-based Approach. In the Proceedings of the Workshop on NLP and Pseudonymisation, in conjunction with the 22nd Nordic Conference on Computational Linguistics (NoDaLiDa), Turku, Finland, September 30, 2019, pdf.
Videos & Presentations
Watch recorded videos and download the presentations…

Research: Privacy-preserving data analysis. We apply tools from information theory to problems related to privacy-preserving data analysis
Speaker: Sara Saeidian, PhD student, saeidian@kth.se
Supervisors: Tobias J. Oechtering, Mikael Skoglund
Click here to watch the recorded video presentation on “Privacy-preserving data analysis”
OUR PRESENTATIONS
Quantifying Membership Privacy via Information Leakage
Sara Saeidian, Giulia Cervia, Tobias J. Oechtering, Mikael Skoglund, “Quantifying Membership Privacy via Information Leakage, IEEE Transactions Information Forensics and Security, Vol.16, pp. 3096-3108, 2021.
Machine learning models are known to memorize the unique properties of individual data points in a training set. This memorization capability can be exploited by several types of attacks to infer information about the training data, most notably, membership inference attacks. In this work, we propose an approach based on information leakage for guaranteeing membership privacy. Specifically, we propose to use a conditional form of the notion of maximal leakage to quantify the information leaking about individual data entries in a dataset, i.e., the entrywise information leakage.
We apply our privacy analysis to the Private Aggregation of Teacher Ensembles (PATE) framework for privacy-preserving classification of sensitive data and prove that the entrywise information leakage of its aggregation mechanism is Schur-concave when the injected noise has a log-concave probability density. The Schur-concavity of this leakage implies that increased consensus among teachers in labelling a query reduces its associated privacy cost. We also derive upper bounds on the entrywise information leakage when the aggregation mechanism uses Laplace distributed noise.
DOWNLOAD THE PRESENTATION HERE: Quantifying Membership Privacy via Information Leakage
About the project
Objective
The research team’s ambition is to develop a new research area in urban development (studies). Well-being in smart cities is the defined research area, focusing on interactions of human-machine-computers or “cyber-physical-human systems” based on human decision-making on an institutional, individual and neurological abstraction level. The smart city of the future is our main application area, as these are complex cyber-physical-human systems. The project will develop a framework for capturing interactions and dynamics in these systems and demonstrate the applications in user case studies.
Background
The health condition of a human being is the basis of individual and social well-being. The driving force for human-social behaviour and many choices individuals make is the desire for well-being, which will manifest in the future of smart cities. Networks, human agents, cyber agents, and physical infrastructure perform feedback and interactions in smart cities. Smart cities can efficiently and sustainably increase human well-being.
Cross-disciplinary collaboration
The research team represents the School of Electrical Engineering and Computer Science (EECS, KTH), the School of Industrial Engineering and Management (ITM, KTH) and the School of Architecture and the Built Environment (ABE, KTH).
Activities & Results
Find out what’s going on!
Activities, awards, and other outputs
- HiSS Workshop 2021: From smart to intelligent cities: A human-social choice? Smart cities of a digitalized society are envisioned as cyber-physical-human systems of sustainable economic growth that enhance human well-being. The grand challenge for designing and developing smart cities is to achieve mutually beneficial interactions between cyber and human systems where machines learn from humans, and humans learn from machines. Theories of human behaviour are traditionally context-dependent and specialized in economics, education, games, social interactions, management, etc. Smart cities, as cyber-physical-human systems, set a new context for modelling and understanding human-social behaviour at different levels – from neuro-cognition of individual choices to collective decisions and emergence in social networks at multiple time scales.
- A Workshop was held in September 2021 with three online sessions:
- Session 1: 6/9 Interactional Intelligence with speakers Assoc. Prof. Sarah Williams, MIT, Univ.-Prof. Dr. Marcel Schweiker, University Hospital RWTH Aachen, Dr. Umberto
- Fugiglando, MIT.
- Session 2: 13/9 Reflective Intelligence with speakers Prof. Katina Michael, Arizona State University, Assoc. Prof. Esteban Moro, Universidad Carlos III de Madrid and MIT, Prof. Angelia Nedich, Arizona State University,
- Session 3: 20/9 Neuro-cognition Prof. Jerome Busemeyer, Univ of Indiana, Prof. Alan Safney, Radboud University, Prof. Scott Huettel, Duke University
Results
A general objective of the project is to link dominant mechanisms of decision-making and choice between the micro, meso and macro scales that are most relevant for advancing the sustainability agenda in smart cities. The specific objectives are related to theoretical and experimental studies of different aspects of decision-making at micro, meso and macro scales that help answer the following questions:
- Which human choice/decision models are suitable for understanding decision processes, policy making, etc., in the sustainable smart city context
- What aspects of human choices and decisions in the present context can be related to and explained by neuro-cognitive processes?
- How do social network interactions (e.g. collaboration and competition) affect human choices from smart homes to smart cities?
Publications
We like to inspire and share interesting knowledge!
- M. Lenninger, M. Skoglund, P. Herman & A. Kumar. Are single-peaked tuning curves tuned for speed rather than accuracy? Nature Communications (in review).
- M. Lundqvist, S.L. Brincat, M.R. Warden, T.J. Buschman, E.K. Miller & P. Herman. Working memory control dynamics follow principles of spatial computing. Nature Communications (in review).
- M. Molinari, J. Anund Vogel, D. Rolando. Using Living Labs to tackle innovation bottlenecks: the KTH Live-In Lab case study,Applied energy(Extension under review).
- N. Chrysanthidis, F. Fiebig, A. Lansner & P. Herman. “Traces of semantization-from episodic to semantic memory in a spiking cortical network model”, eNeuro, July 2022, 9 (4). https://doi.org/10.1523/ENEURO.0062-22.2022.
- Fontan, V. Cvetkovic, K. H. Johansson. On behavioral changes towards sustainability for connected individuals: a dynamic decision-making approach, in 4th IFAC Workshop on Cyber-Physical Human Systems, Houston, Texas, December 1-2, 2022.
- Taras Kucherenko, Rajmund Nagy, Michael Neff, Hedvig Kjellström, and Gustav Eje Henter. Multimodal analysis of the predictability of hand-gesture properties. In
- International Conference on Autonomous Agents and Multi-Agent Systems, 2022.
- M. Lundqvist, J. Rose, S.L. Brincat, M.R. Warden, T.J. Buschman, P. Herman, & E.K. Miller. “Reduced variability of bursting activity during working memory.” Scientific Reports 12, no. 1 (2022): 1-10.
- N.B. Ravichandran, A. Lansner & P. Herman. “Brain-like combination of feedforward and recurrent network components achieves prototype extraction and robust pattern recognition”. In: Machine Learning, Optimization, and Data Science. LOD 2022. Lecture Notes in Computer Science, Springer, Cham
- D. Rolando, W. Mazzotti, M. Molinari. Long-Term Evaluation of Comfort, Indoor Air Quality and Energy Performance in Buildings: The Case of the KTH Live-In Lab Testbeds, Energies, vol. 15, no. 14, pp. 4955, 2022.
- N. Chrysanthidis, F. Fiebig, A. Lansner & P. Herman. “Semantization of episodic memory in a spiking cortical attractor network model”, Journal of Computational Neuroscience, vol. 49, no. SUPPL 1, pp. S86–S87, 2021.
- A. Karvonen, V. Cvetkovic, P. Herman, K.H. Johansson, H. Kjellström, M. Molinari & M. Skoglund. “The ‘New Urban Science’: towards the interdisciplinary and transdisciplinary pursuit of sustainable transformations.” Urban Transformations 3, no. 1 (2021): 1-13.
- M. Molinari, J. Anund Vogel, D. Rolando. Using Living Labs to tackle innovation bottlenecks: the KTH Live-In Lab case study, in Energy Proceedings – Applied Energy Symposium: MIT A+B, 2021.
- N.B. Ravichandran, A. Lansner & P. Herman. “Semi-supervised learning with Bayesian Confidence Propagation Neural Network”, in Proc. European Symposium on Artificial Neural Networks (ESANN) 2021. doi.org/10.14428/esann/2021.es2021-156.
- Ruibo Tu, Kun Zhang, Hedvig Kjellström, and Cheng Zhang. Optimal transport for causal discovery. In International Conference on Learning Representations, 2022.
- Carles Balsells Rodas, Ruibo Tu, and Hedvig Kjellström. Causal discovery from conditionally stationary time-series, arXiv:2110.06257, 2021.
- M. Lenninger, M. Skoglund, P. Herman and A. Kumar. Bandwidth expansion in the brain: Optimal encoding manifolds for population coding. In Cosyne, 2021.
- S. Molavipour, G. Bassi, and M. Skoglund. On neural estimators for conditional mutual information using nearest neighbors sampling. IEEE Transactions on Signal Processing 69:766-780, 2021.
- M. Sorkhei, G. Eje Henter, and H. Kjellström. Full-Glow: Fully conditional Glow for more realistic image generation. In DAGM German Conference on Pattern Recognition, 2021.
- Chenda Zhang and Hedvig Kjellström. A subjective model of human decision making
- based on Quantum Decision Theory, arXiv:2101.05851, 2021.
- M. Molinari and D. Rolando. Digital twin of the Live-In Lab Testbed KTH: Development and calibration. In Buildsim Nordic, 2020.
- D. Rolando and M. Molinari. Development of a comfort platform for user feedback: The experience of the KTH Live-In Lab. In International Conference on Applied Energy, 2020.
- E. Stefansson, F. J. Jiang, E. Nekouei, H. Nilsson, and K. H. Johansson. Modeling the decision-making in human driver overtaking. In IFAC World Congress, 2020.
- Y. Yi, L. Shan, P. E. Paré, and K. H. Johansson. Edge deletion algorithms for minimizing spread in SIR epidemic models. arXiv preprint arXiv:2011.11087, 2020.