
About the project
Objective
In this seed project, we aim to develop a roadmap starting from Industry 4.0 (launched in 2011) to reach Industry 5.0 with a forward-looking agenda with 2030 as a target. The aim is to develop the Roadmap for Industry 5.0 and beyond, which drives sustainability. The main objectives of the project include,
- To emphasise how synergies can be obtained among the many related efforts at KTH, with partners, and in collaboration between KTH and its strategic partners.
- To find out how current research at KTH responds to the new requirements and what future research themes are proposed with a five-year perspective.
- Engage industry and stakeholder interaction through workshops and establish collaboration for national and international projects (industrial and research projects) in the direction of the roadmap.
The scope of the project is wide and varied. This calls for a diverse network of people working on this project. Therefore, we have put together a strong team of professors, assistant professors, researchers, and post-docs representing two different schools and several departments at KTH. The Industrial digitalization workgroup and reference group support this diverse project team. The project’s results, i.e., the roadmap, will enable industries and academia to guide toward Industry 5.0. This pioneering research work will also help KTH enhance its education and research profiles.
Background
Industry 4.0 has shifted the manufacturing industries greatly towards digitalization. It uses cyber-physical systems to integrate information and communication technologies into production and automation. This has greatly transformed industrial practices but lacked focus on social aspects. In addition, industries will have to meet climate and sustainability targets. Industry 5.0 – or Society 5.0 – aims to address social and sustainability challenges with the help of the integration of physical and virtual spaces that would be achieved by Industry 4.0. Together with technological evolution, the societal characteristics of the social generations have evolved, too. Now, we focus on the industrial transformation from the technology-centric view of Industry 4.0 towards a socio-technical and sustainable view of Industry 5.0.
Crossdisciplinary collaboration
The team’s researchers represent several KTH Royal Institute of Technology departments.
About the project
Objective
This seed project aims to support the Digital Futures (DF) Digitalized Industry Working Group by strengthening the international research focus on industrial digitalization, driving sustainability and addressing related complexity from a systems thinking and engineering point of view. The overall objectives of this seed project are (1) to create a European network of leading research institutions, industry and other stakeholders and (2) to write a proposal for a suitable EU project to support this network. We primarily target an EU COST Action but will also consider other instruments.
Background
There are common challenges in sustainability in the manufacturing, transport, energy, water management, and building sectors, as well as related methodologies to deal with the associated socio-technical complexity. There is a fragmentation of competencies in the use of digitalization to support sustainable development and also related to systems thinking/engineering. With the targeted network, we intend to try to overcome this fragmentation.
Cross-disciplinary collaboration
The PI and co-PIs are spread over two different KTH schools. Each PI needs international collaboration as we aim to apply for a proposal to build an EU network. The partners in the ongoing proposal involve eleven countries so far, >50% COSTInclusiveness Target Countries. We have had one in-person meeting at KTH on 12-13 August 2024 (see photo) and plan for the next meeting in person on 14 October 2024. Several online meetings have taken place since the start of the project.
Contacts: Ellen Bergseth, Martin Törngren, Yongkuk Jeong
About the project
Objective
This research project aims to design a threat modelling and attack simulation language, insuranceLang, for cyber insurance. Testing and validating the domain-specific language will be done using data from the insurance industry. Cyber insurances are fairly new, and their models are simplistic and highly generalized. One reason for this is the lack of relevant historical data on insured losses. As a consequence, cyber insurance is probably not used optimally. In particular, some industries cannot offer appropriate insurance coverage because their risks cannot be assessed.
Background
Society is getting more digitalized. This entails great opportunities but also novel cyber risks, which can be difficult to assess. An adequate understanding of cyber risk is crucial since cybersecurity is a prerequisite for successful industrial transformation and digitalization. Thus, there is great potential for overcoming some of these cyber insurance challenges. More precisely, the use of attack simulations based on system architecture (threat) models is a promising avenue for analyzing the cybersecurity posture of a system. Suppose such analyses were to become more widely used by insurers. In that case, that could enable more precise risk assessment, a better understanding of risk-reducing measures, and insights into risks that have been uninsurable until now.
Crossdisciplinary collaboration
The researchers in the team represent the School of Electrical Engineering & Computer Science, KTH and the Division of Digital Systems, RISE.
In addition to the PIs, Carlos Barreto works in this project as a postdoctoral researcher funded by Digital Futures.
About the project
Objective
The project aims to develop biodegradable recording platforms for digital technologies that capture biological signals and safely integrate them into life and the environment. This project develops the first example of a biodegradable technology that degrade after disposal by the action of specific enzymes. To reach such a goal, we pursue an interdisciplinary approach combining expertise in materials chemistry and rational polymer design, organic electronics (device fabrication), and biology (biodegradation and toxicity).
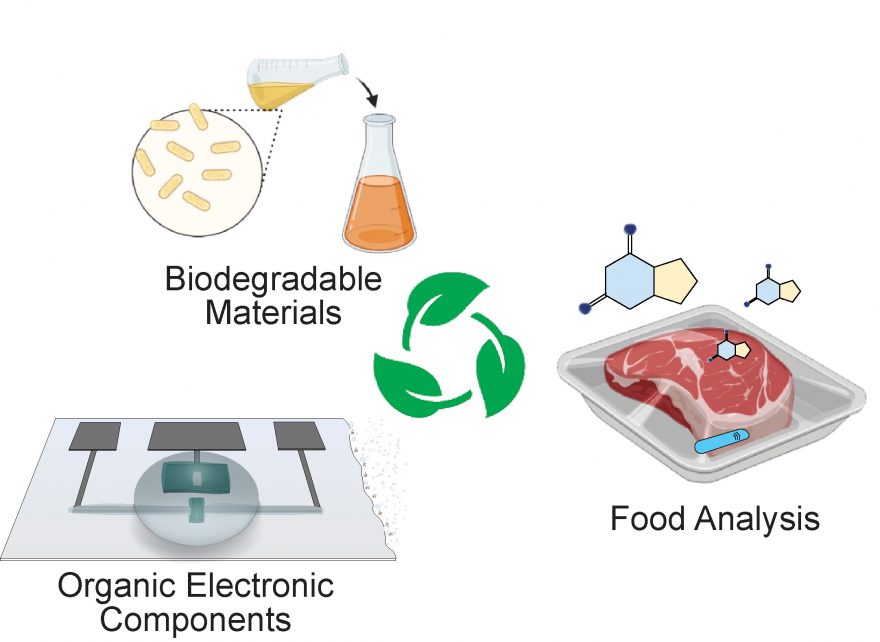
Background
As electronics become increasingly integrated into our daily lives, there is a growing demand for technologies that decompose after a period of stable operation without leaving a permanent mark (transience). For consumer electronics, such as digital packaging, biodegradable solutions are set to contribute towards the Swedish and EU goal of reducing waste and promoting greener technologies by 2030. A key challenge is to develop components combining stable operation in environmental conditions (humidity, pH, etc.) and safe biodegradation into non-toxic products.
Cross-disciplinary collaboration
The researchers in the team represent the Department of Engineering Mechanics at KTH SCI and the Department of Fibre and Polymer Technology at KTH CBH.
About the project
Objective
The Enabling Machine-Learning Intelligence for Network Cybersecurity (EMERGENCE) aims at enabling machine-learning-based analysis of high-speed network cybersecurity data. The first part of the project focuses on extracting the relevant fine-grained network metrics directly in the network devices and transforming these collected metrics into summaries that can be easily extracted from the devices. The second part of the project takes these summaries and feeds them into a machine learning system that is tailored to detect security attacks and performance-related issues. A key idea in the project is to leverage programmable network technologies that allow performing ad-hoc operations at the speed of the network before the summaries are sent to the slower machine learning systems.
One of the envisioned contributions of the project is the design and implementation of a framework that reconciles the different speeds at which today’s networks and machine learning systems operate.
Background
During the current global pandemic crisis, the Internet has played an essential role in allowing different parts of our society to continue operating without interruptions to the largest extent possible. However, the recent wave of cyber-attacks targeting the Internet infrastructure has raised concerns about the resilience of the Internet infrastructure. In contrast to general cybersecurity threats, which affect end-host systems, Internet-based network attacks target the core infrastructure of the Internet that is responsible for interconnecting all the billions of users, devices, and services together. Machine learning techniques to detect network-based cyber-attacks have long been limited by two unique aspects of the networking domain. First, network data is inherently volatile as traffic flows through a network without being stored. Second, network technologies are ill-suited for extracting fine-grained network information from high-speed networking devices. Both challenges will be addressed by relying on the emerging high-speed programmable network devices.
Crossdisciplinary collaboration
The researchers in the team represent the School of Electrical Engineering & Computer Science, KTH, and the Connected Intelligence unit at RISE Research Institutes of Sweden.
About the project
Objective
SHIFT-DT aims to transcend the current advancements in ship design and production technologies by establishing a framework that incorporates the decarbonization of shipping by marrying holistic ship design with digitalized ship production and logistics through the application of digital twins based on the model-based systems engineering method. This novel approach positions digital twin technology as the next-generation solution for sustainable ship design and production. By realizing these research objectives, we can contribute significantly to integrating digital and innovative solutions in sustainable ship design and production.
Background
Digitalization and decarbonization are the transformative forces that will shape the future of shipping. Through technologies like Digital Twins (DTs), digitalization has the potential to revolutionize ship design and production, thereby advancing decarbonization. Extensive literature reviews, however, suggest that the application of DTs in ship design and production is nascent. Studies involving ships designed entirely with DTs are notably lacking, presenting the maritime industry with the significant challenge of establishing a new design methodology for ships using DT technology. This challenge extends to the broader manufacturing industry, where new design processes are evolving slowly and implementing DTs in ship production is an emerging, complex concept.
Crossdisciplinary collaboration
A collaboration has been established between the KTH Center for Naval Architecture at the Department of Engineering Mechanics and the Production Logistics Research Group at the Department of Production Engineering. This multidisciplinary team, comprising recognized experts in ship design and production, is exceptionally positioned to lead the digitalization of sustainable ship design and production.
About the project
Objective
In Emergence 2.0, we aim to build reliable, secure, high-speed edge networks that enable the deployment of mission-critical applications, such as remote vehicle driving and industrial sensor & actuator control. We will design a novel system for enabling fine-grained network visibility and intelligent control planes that are i) reactive to quickly detect and react to anomalies or attacks in edge networks and IoT networks, ii) accurate to avoid missing sophisticated attacks or issue unwanted alerts without reason, iii) expressive, to support complex analysis of data and packet processing pipelines using ML classifiers, and iv) efficient, to consume up to 10x less energy resources compared to state of the art.
Background
Detecting cyber-attacks, failures, misconfigurations, or sudden changes in the traffic workload must rely on two components: i) an accurate/reactive network monitoring system that provides network operators with fine-grained visibility into the underlying network conditions and ii) an intelligent control plane that is fed with such visibility information and learns to distinguish different events that will trigger mitigation operations (e.g., filtering malicious traffic).
Today’s networks rely on general-purpose CPU servers equipped with large memories to support fine-grained visibility of a small fraction (1%) of the forwarded traffic (i.e., user-faced traffic). Even for such small amounts of traffic, recent work has shown that a network must deploy >100 general-purpose, power-hungry CPU-based servers to process a single terabit of traffic per second, costing millions of dollars to build and power with electricity. Today’s data centre networks must support thousands of terabits per second of traffic across their cloud and edge data centre infrastructure.
Crossdisciplinary collaboration
The researchers in the team represent the KTH School of Electrical Engineering and Computer Science, the Department of Computer Science and the Connected Intelligence unit at RISE Research Institutes of Sweden.